ImageSpirit: Verbal Guided Image Parsing
- Ming-Ming Cheng1
- Shuai Zheng1
- Wen-Yan Lin2
- Vibhav Vineet2
- Paul Sturgess2
- Nigel Crook2
- Niloy J. Mitra3
- Philip Torr1
- 1University of Oxford
- 2Oxford Brookes University
- 3University College London
ACM Transactions on Graphics 2014
Abstract
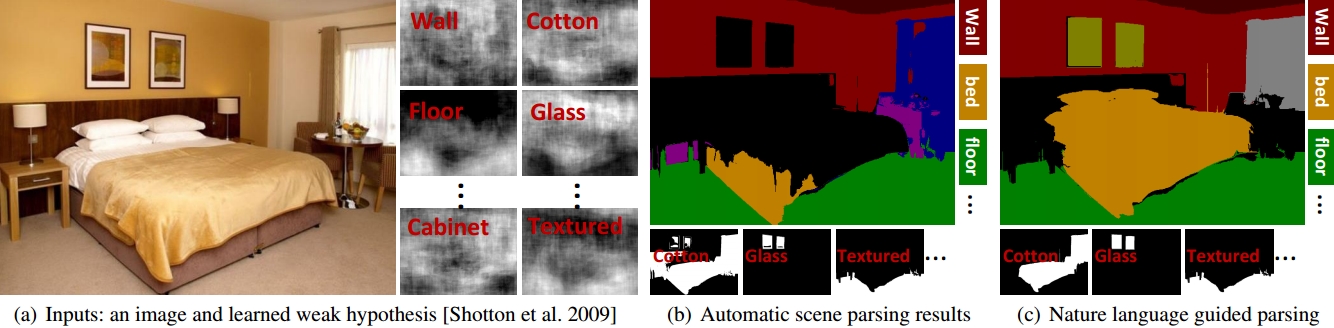
Humans describe images in terms of nouns and adjectives while algorithms operate on images represented as sets of pixels. Bridging this gap between how humans would like to access images versus their typical representation is the goal of image parsing, which involves assigning object and attribute labels to pixel. In this paper we propose treating nouns as object labels and adjectives as visual attribute labels. This allows us to formulate the image parsing problem as one of jointly estimating per-pixel object and attribute labels from a set of training images. We propose an efficient (interactive time) solution. Using the extracted labels as handles, our system empowers a user to verbally refine the results. This enables hands-free parsing of an image into pixel-wise object/attribute labels that correspond to human semantics. Verbally selecting objects of interests enables a novel and natural interaction modality that can possibly be used to interact with new generation devices (e.g. smart phones, Google Glass, living room devices). We demonstrate our system on a large number of real-world images with varying complexity. To help understand the tradeoffs compared to traditional mouse based interactions, results are reported for both a large scale quantitative evaluation and a user study.
Acknowledgement
We thank the reviewers for their comments and suggestions for improving the paper. This work was supported in part by an UCL Impact award, the ERC Starting Grant SmartGeometry (StG-2013- 335373), NSFC (No. 61402402), and gifts from Adobe Research.
Bibtex
@article{cheng2014imagespirit,
title={ImageSpirit: Verbal Guided Image Parsing},
author={Cheng, Ming-Ming and Zheng, Shuai and Lin, Wen-Yan and Vineet, Vibhav and Sturgess, Paul
and Crook, Nigel and Mitra, Niloy and Torr, Philip},
journal={ACM Transactions on Graphics},
year={2014}
}


