Scene Structure Inference through Scene Map Estimation
- Moos Hueting1
- Viorica Pătrăucean2
- Maks Ovsjanikov3
- Niloy J. Mitra1
1University College London 2University of Cambridge 3LIX, École Polytechnique
VMV 2016

Given a single RGB image (left), we propose a pipeline to generate a scene map (middle) in the form of a floorplan with grid
locations for the discovered objects. The resulting scene map can then be potentially used to generate a 3D scene mockup (right). Please note
that our system does not yet support pose estimation; hence in the mockup the objects are in default front-facing orientations.
Abstract
Understanding indoor scene structure from a single RGB image is useful for a wide variety of applications ranging from the
editing of scenes to the mining of statistics about space utilization. Most efforts in scene understanding focus on extraction
of either dense information such as pixel-level depth or semantic labels, or very sparse information such as bounding boxes
obtained through object detection. In this paper we propose the concept of a scene map, a coarse scene representation, which
describes the locations of the objects present in the scene from a top-down view (i.e., as they are positioned on the floor), as
well as a pipeline to extract such a map from a single RGB image. To this end, we use a synthetic rendering pipeline, which
supplies an adapted CNN with virtually unlimited training data. We quantitatively evaluate our results, showing that we clearly
outperform a dense baseline approach, and argue that scene maps provide a useful representation for abstract indoor scene
understanding.
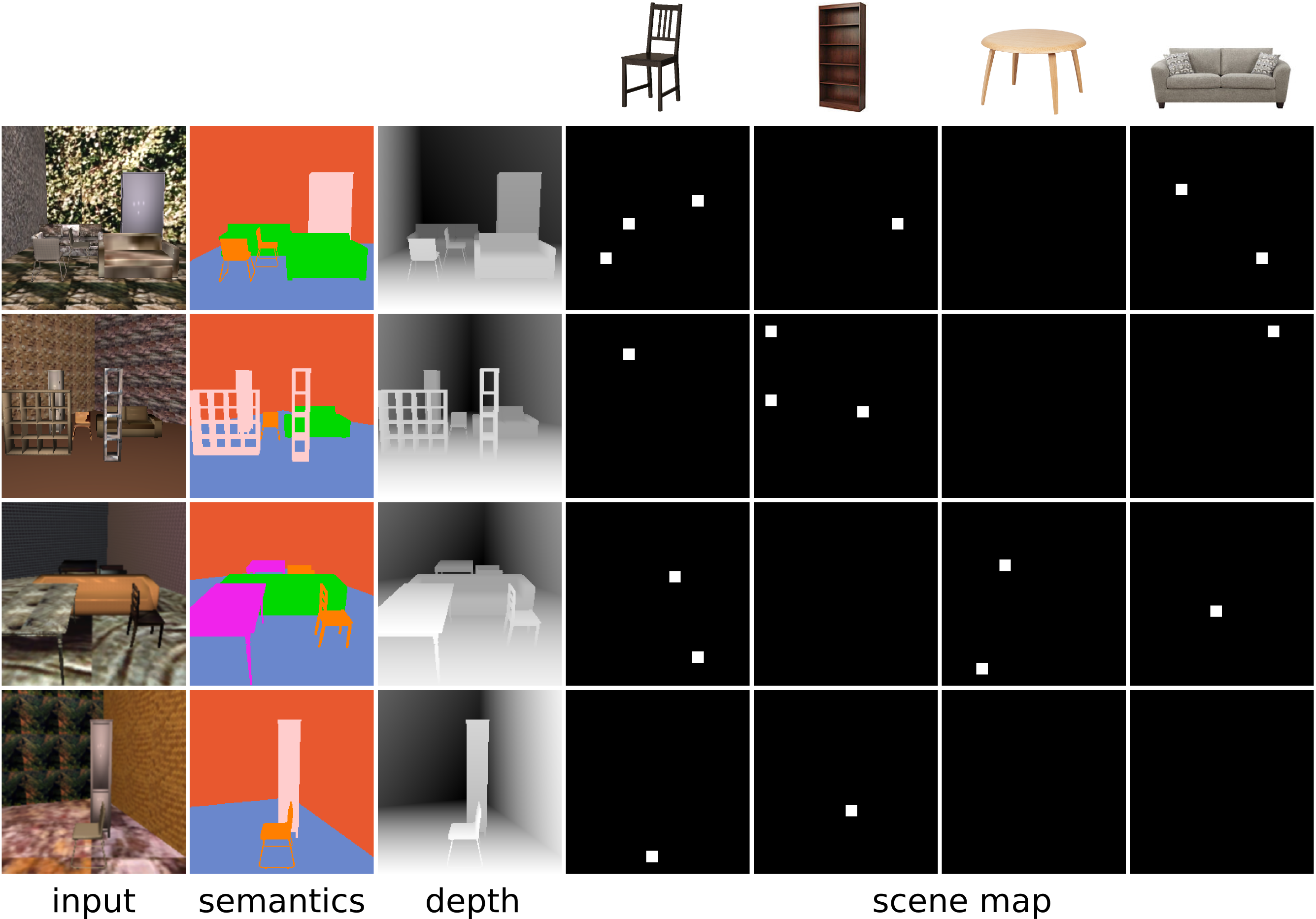
Scene Map representation

A scene map describes the scene on a per-class basis from
a top-down view corresponding to an input RGB image. A white
square indicates the presence of an instance of that particular class
at that location. Here we show the groundtruth scene map for the input scene on the left.
Scene Map representation

Our aim is to automatically infer scene maps from single frame RGB input images. We modify the well-known VGG network architecture to work for this purpose.
Scene Map representation
To offset a lack of existing training data for our purposes, we implement a training data generation pipeline that feeds an endless stream of randomly generated indoor scenes together with segmentation, depth, and scenemap to our training pipeline.
Scene Map representation

We evaluate our system on a synthetic dataset consisting of models and textures not seen at training time. A green square indicates a true positive, a yellow square a false positive, and a red square a false negative classification. In most cases, the errors can be explained as slight misplacements of the ground truth.
Bibtex
@article{HuetingEtAl:SceneStructureInference:2016,
title = {Scene Structure Inference through Scene Map Estimation},
author = {Moos Hueting and Viorica Pătrăucean and Maks Ovsjanikov and Niloy J. Mitra},
year = {2016},
journal = {VMV}
}
Acknowledgements
This work is in part supported by the Microsoft
PhD fellowship program, EPSRC grant number EP/L010917/1, Marie-Curie
CIG-334283, a CNRS chaire d’excellence, chaire Jean Marjoulet from École
Polytechnique, FUI project TANDEM 2, a Google Focused Research Award,
and ERC Starting Grant SmartGeometry (StG-2013-335373).
Links

Paper
(Coming soon)

Data and Code (Coming soon)