Transferring Image-based Edits for Multi-Channel Compositing
- James W. Hennessey1
- Wilmot Li2
- Bryan Russell2
- Eli Shechtman2
- Niloy J. Mitra1
1University College London 2Adobe Research
SIGGRAPH-Asia 2017
Abstract
A common way to generate high-quality product images is to start with a physically-based render of a 3D scene, apply image-based edits on individual render channels, and then composite the edited channels together (in some cases, on top of a background photograph). This workflow requires users to manually select the right render channels, prescribe channel-specific masks, and set appropriate edit parameters. Unfortunately, such edits cannot be easily reused for global variations of the original scene, such as a rigid-body transformation of the 3D objects or a modified viewpoint, which discourages iterative refinement of both global scene changes and image-based edits. We propose a method to automatically transfer such user edits across variations of object geometry, illumination, and viewpoint. This transfer problem is challenging since many edits may be visually plausible but non-physical, with a successful transfer dependent on an unknown set of scene attributes that may include both photometric and non-photometric features. The problem of transferring edits is challenging as on the one hand they often involve multiple channels, while on the other hand adding too many channels can easily result in corrupted transfers. To address this challenge, we present a transfer algorithm that extends the image analogies formulation to include an augmented set of photometric and non-photometric guidance channels and, more importantly, adaptively estimate weights for the various candidate channels in a way that matches the characteristics of each individual edit. We demonstrate our algorithm on a variety of complex edit-transfer scenarios for creating high-quality product images.
System Overview

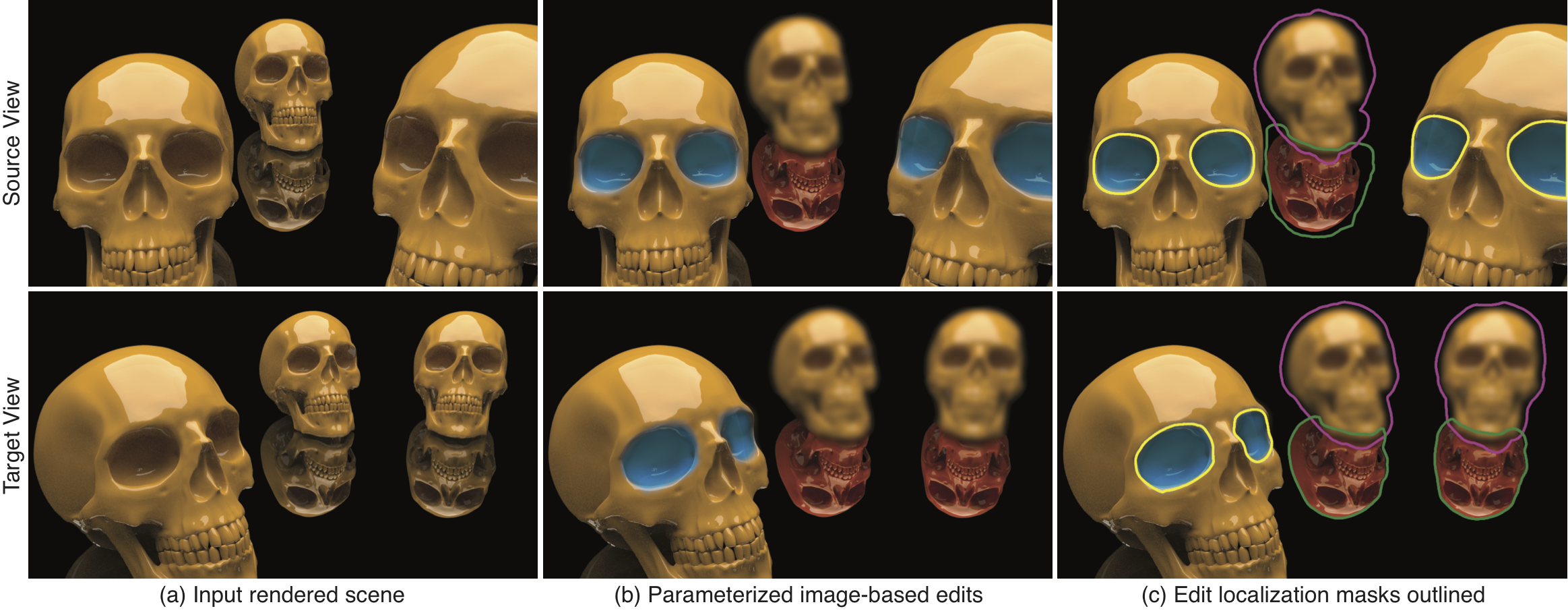
Starting from an input source view of a rendered 3D scene, along with corresponding augmented render channels, the user may make a number of 2D edits. To make an edit, the user first outlines a region of interest (ROI). Our method then automatically determines a region mask and a selection of one or more relevant photometric render channels for the edit. The user then makes a parametric adjustment within the region mask to the selected channels to obtain an edited source view. In this example, the user removes the wine glass reflection and adjusts highlights on the labels. The user may then modify the 3D scene by replacing the 3D objects or changing the viewpoint to yield a target view. Our system automatically transfers the user edits from the source view to the target view. Text on green background denote the user interaction and blue text the computational aspects of our method.
Results
To best view the transferred edits, please see the electronic paper version, the supplemental video, and the suppl. PDF.

Bibtex
Acknowledgements
We thank our reviewers for their invaluable comments and the user study participants for their time and feedback. We also thank Moos Hueting, Tom Kelly, Carlo Innamorati, Aron Monszpart, Robin Roussel and Tuanfeng Yang Wang for their suggestions and support. We particularly thank Paul Guerrero for his help with the perceptual user study and Kaan Yücer for generating the Transfusive Image Manipulation [Yücer et al. 2012] comparisons. This work was partially funded by the ERC Starting Grant SmartGeometry (StG-2013-335373), EPSRC EngD Centre EP/G037159/1, a Rabin Ezra Trust Scholarship and gifts from Adobe.