SeeThrough: Finding Chairs in Heavily Occluded Indoor Scene Images
- Moos Hueting1
- Pradyumna Reddy1
- Ersin Yumer2
- Vladimir G. Kim2
- Nathan Carr2
- Niloy J. Mitra1
1University College London 2Adobe Research
3DV 2018
Selected for Oral presentation
(Left) A single input image is provided of an indoor scene. (Right) By finding local keypoints, generating candidate placements and selecting among these placements using a model of object co-occurrence, we are able to faithfully reconstruct the location of the chairs in the scene, even those that are heavily occluded. (Bottom) Our proposed algorithm SeeThrough continues to have a high success rate under medium to heavy occlusion.
Abstract
Discovering 3D arrangements of objects from single indoor images is important given its many applications including interior design, content creation, etc.
Although heavily researched in the recent years, existing approaches break down under medium or heavy occlusion as the core object detection module starts failing in absence of directly visible cues.
Instead, we take into account holistic contextual 3D information, exploiting the fact that objects in indoor scenes co-occur mostly in typical near-regular configurations.
First, we use a neural network trained on real indoor annotated images to extract 2D keypoints, and feed them to a 3D candidate object generation
stage. Then, we solve a global selection problem among these 3D candidates using
pairwise co-occurrence statistics discovered from a large 3D scene database.
We iterate the process allowing for candidates with low keypoint
response to be incrementally detected based on the location of the already discovered nearby objects.
Focusing on chairs, we demonstrate significant performance improvement over combinations of state-of-the-art methods, especially for scenes with moderately to severely occluded
objects.
Overview
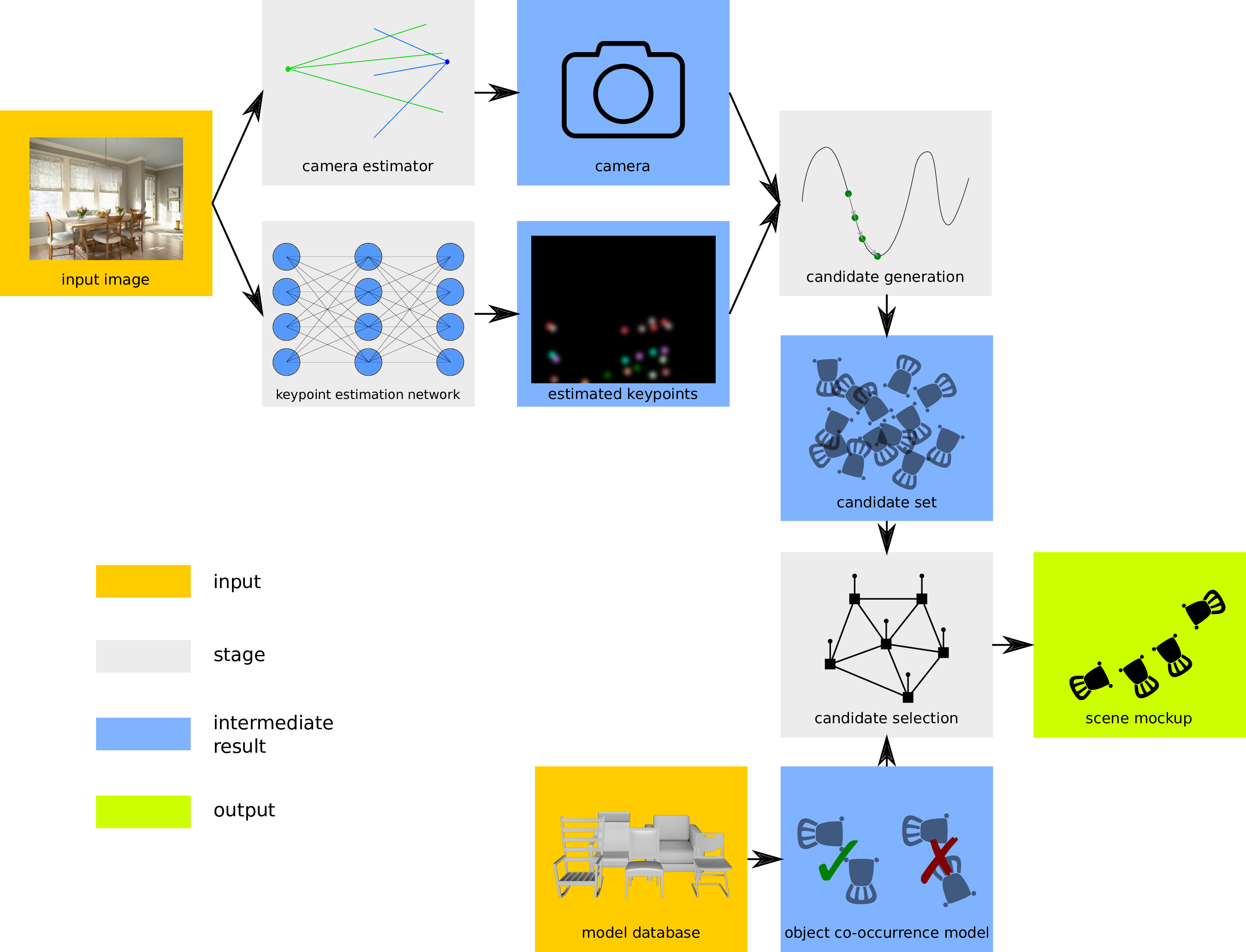 In a scene with many chairs, we observe that the environment is not important for the recognition of the unoccluded chair - the shape of the object is clearly visible and
immediately recognizable. However, under occlusion, the
task of recognizing the object necessitates adding 3D contextual information. State-of-the-art methods based on FRCNN (Ren et al. 2015) correctly detect chairs that are visible, but miss partially occluded ones. However, under occlusion, the
task of recognition becomes easier with more contextual and cooccurence information.
Motivated by the above insight, we design SeeThrough to run in three key steps:
In a scene with many chairs, we observe that the environment is not important for the recognition of the unoccluded chair - the shape of the object is clearly visible and
immediately recognizable. However, under occlusion, the
task of recognizing the object necessitates adding 3D contextual information. State-of-the-art methods based on FRCNN (Ren et al. 2015) correctly detect chairs that are visible, but miss partially occluded ones. However, under occlusion, the
task of recognition becomes easier with more contextual and cooccurence information.
Motivated by the above insight, we design SeeThrough to run in three key steps:
- an image-space keypoint detection trained on AMT-annotated real photographs;
- a candidate generation step that takes the estimated camera to lift detected 2D keypoints to 3D (deformable) model candidates; and
- an iterative scene mockup stage where we solve a selection problem to extract a scene arrangement that proposes a plausible object layout using a common object co-occurrence prior.
Results
To best view the results, please see the electronic paper version and the suppl. PDF.

Qualitative comparison with the state-of-the-art baseline methods: SeeingChairs (orange) and FasterRCNN3D (blue) against SeeThrough (green). Annotated groundtruth poses (gray) are provided for reference in the top view. Note that our approach both detects more chairs and correctly aligns them compared to the others.
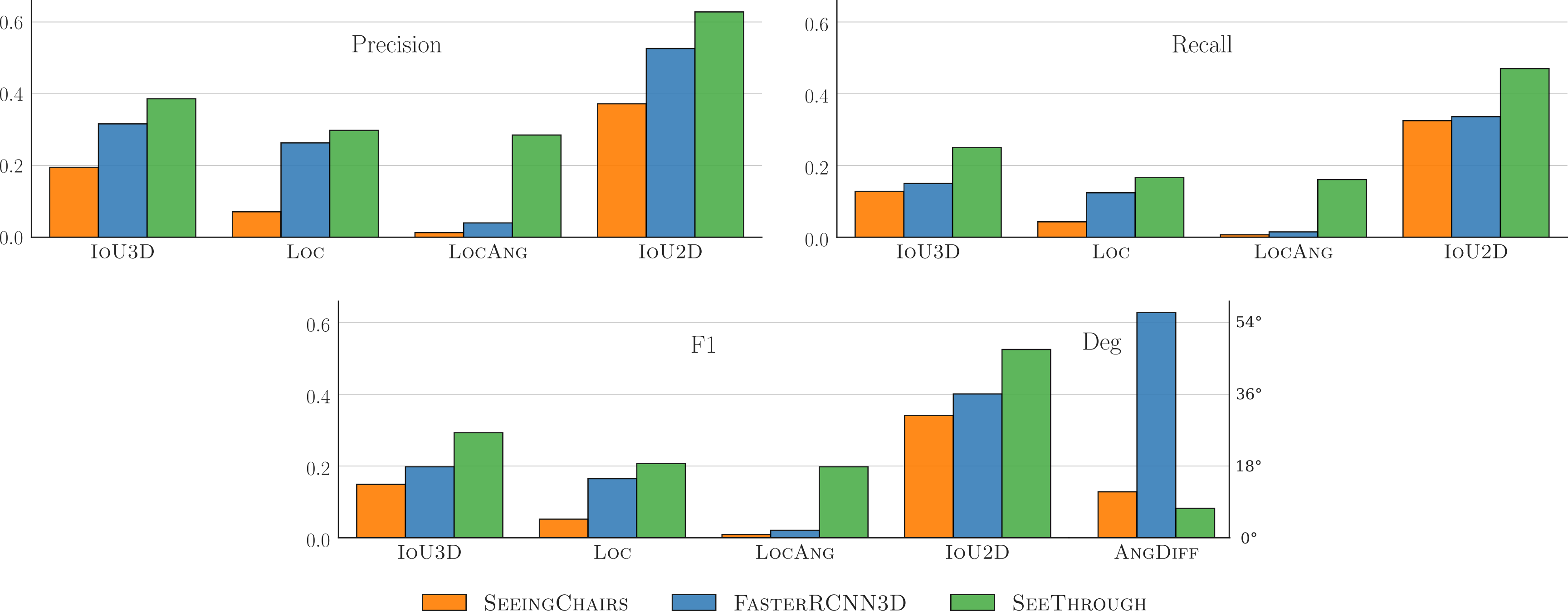
Quantitative comparison with the state-of-the-art baseline methods: SeeingChairs (orange) and FasterRCNN3D (blue) against SeeThrough (green). Higher is better across all measures, except for AngDiff, where lower is better. We outperform the baselines significantly across all measures.
Bibtex
@inproceedings{seeThrough_HuetingReddy_3DV18,
Author = {Moos Hueting and Pradyumna Reddy and Ersin Yumer and
Vladimir G. Kim and Nathan Carr and Niloy J. Mitra},
booktitle = {Proceedings of International Conference on 3DVision ({3DV})},
note = {selected for oral presentation},
Title = {SeeThrough: Finding Objects in Heavily Occluded Indoor Scene Images},
Year = {2018}}
Acknowledgements
We thank Aron Monszpart, James Hennessey, Paul Guerrero and Yu-Shiang Wong for their invaluable help, suggestions, and support. This work was partially funded by the ERC Starting Grant SmartGeometry (StG-2013-335373), a Rabin Ezra Trust Scholarship and gifts from Adobe.