Dynamic Neural Garments
Meng Zhang1 Tuanfeng Wang2 Duygu Ceylan2 Niloy J. Mitra1,2
1University College London 2 Adobe Research
Siggraph Asia 2021
Abstract
A vital task of the wider digital human effort is the creation of realistic garments on digital avatars, both in the form of characteristic fold patterns and wrinkles in static frames as well as richness of garment dynamics under avatars' motion. Existing workflow of modeling, simulation, and rendering closely replicates the physics behind real garments, but is tedious and requires repeating most of the workflow under changes to characters' motion, camera angle, or garment resizing. Although data-driven solutions exist, they either focus on static scenarios or only handle dynamics of tight garments. We present a solution that, at test time, takes in body joint motion to directly produce realistic dynamic garment image sequences. Specifically, given the target joint motion sequence of an avatar, we propose dynamic neural garments to jointly simulate and render plausible dynamic garment appearance from an unseen viewpoint. Technically, our solution generates a coarse garment proxy sequence, learns deep dynamic features attached to this template, and neurally renders the features to produce appearance changes such as folds, wrinkles, and silhouettes. We demonstrate generalization behavior to both unseen motion and unseen camera views. Further, our network can be fine-tuned to adopt to new body shape and/or background images. We also provide comparisons against existing neural rendering and image sequence translation approaches, and report clear quantitative improvements.
Pipeline
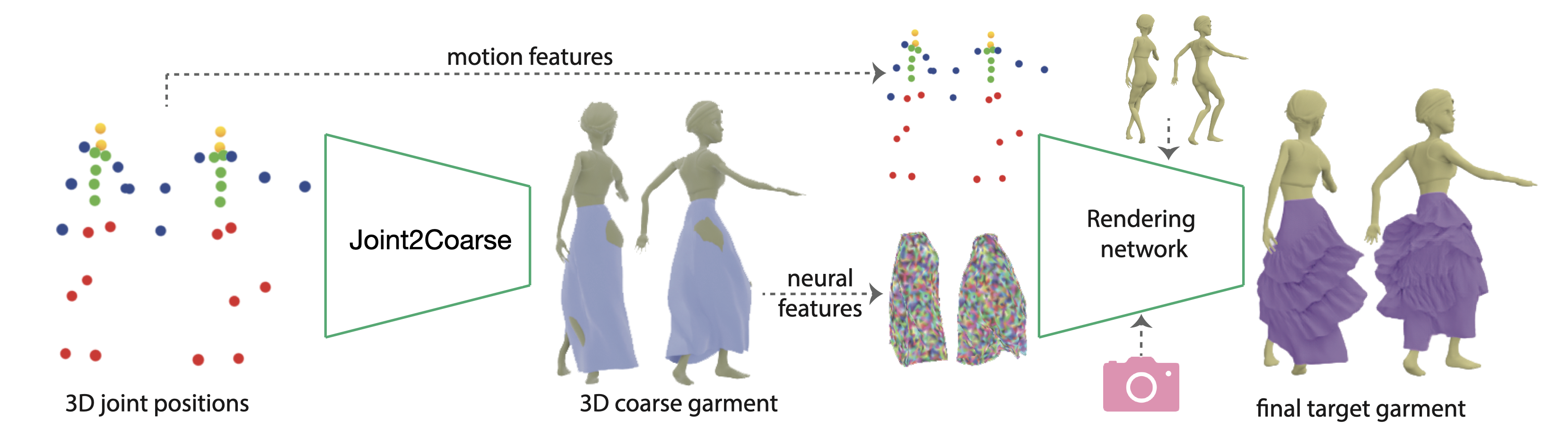
Starting from a body motion sequence, we first synthesize how a coarse garment proxy would deform in 3D. We then learn deep dynamic features on the coarse template to synthesize the final appearance of the target garment from a desired viewpoint. Note that the target garment is different from the coarse template geometrically and hence both the overall outline of the garment and the dynamic appearance, i.e., folds, silhouettes, and wrinkles, are significantly different.
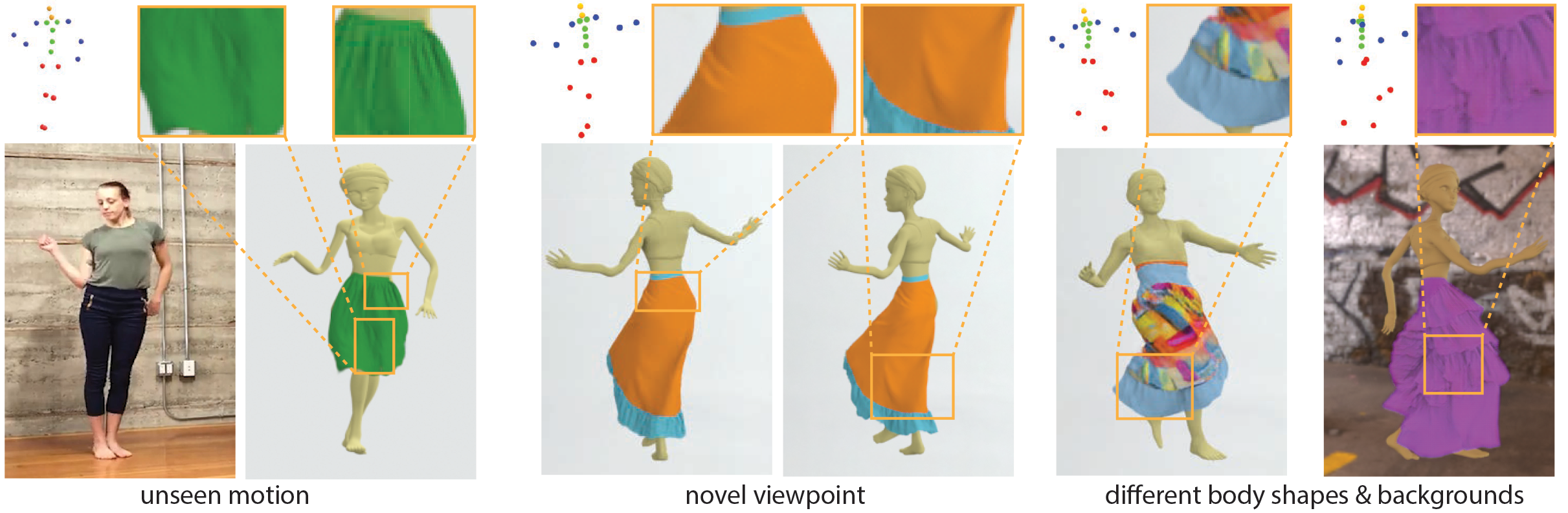
Results to show the generalization ability of our method
(i) Unseen views. we test how our method generalizes to unseen viewpoints. Compared to simply retrieving the nearest viewpoints from the training set, our method can generate temporally smooth image sequences for different garments types.

(ii) Unseen motions. We demonstrate the generalization capability of our method for unseen motion sequences. Note that, for all 3 target skirt styles, we use the same plain long skirt as the coarse template.


(iii) Different body shapes. Given the dynamic neural rendering network trained for a thin body, we can finetune it to generalize across different body shapes.


(iv) Different background. Our dynamic neural renderer can easily be fine-tuned with a few examples to generalize to different backgrounds showing various illumination conditions.
Driving 3D charator with real capture

Our method can be combined with 3D body motion estimation methods to guide the synthesis of the garment appearance based on the actor's performance.
Acknowledgements
The authors would like to thank the anonymous reviewers for their constructive comments, adobe fuse for providing us the virtual character and mixamo for the motion sequence, Jinglong Yang and Sida Peng for their helping on the comparisons. This work was partially supported by the ERC SmartGeometry grant and gifts from Adobe Research.