Im2Vec: Synthesizing Vector Graphics without Vector Supervision
Pradyumna Reddy1 Michael Gharbi2 Michal Lukac2 Niloy J. Mitra1,2
1University College London 2 Adobe Research
CVPR 2021 Oral Presentation
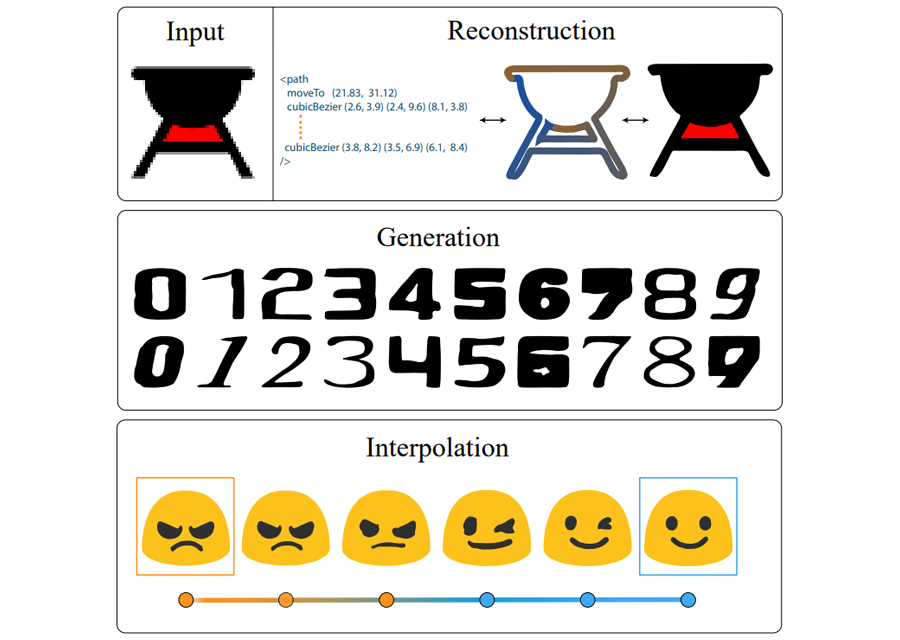
Abstract
Vector graphics are widely used to represent fonts, logos, digital artworks, and graphic designs. But, while a vast body of work has focused on generative algorithms for raster images, only a handful of options exists for vector graphics. One can always rasterize the input graphic and resort to image-based generative approaches, but this negates the advantages of the vector representation. The current alternative is to use specialized models that require explicit supervision on the vector graphics representation at training time. This is not ideal because large-scale high quality vector-graphics datasets are difficult to obtain. Furthermore, the vector representation for a given design is not unique, so models that supervise on the vector representation are unnecessarily constrained. Instead, we propose a new neural network that can generate complex vector graphics with varying topologies, and only requires indirect supervision from readily-available raster training images (i.e., with no vector counterparts). To enable this, we use a differentiable rasterization pipeline that renders the generated vector shapes and composites them together onto a raster canvas. We demonstrate our method on a range of datasets, and provide comparison with state-of-the-art SVG-VAE and DeepSVG, both of which require explicit vector graphics supervision. Finally, we also demonstrate our approach on the MNIST dataset, for which no groundtruth vector representation is available.
Interpolations

![]()
We show interpolations between source–target pairs on the EMOJIS and ICONS datasets.




We show interpolations on the FONTS dataset. Unlike previous work, Im2Vec enables plausible interpolation even across significant changes in shape. For instance, the stem of the digit ‘9’ naturally curls along the interpolation path.
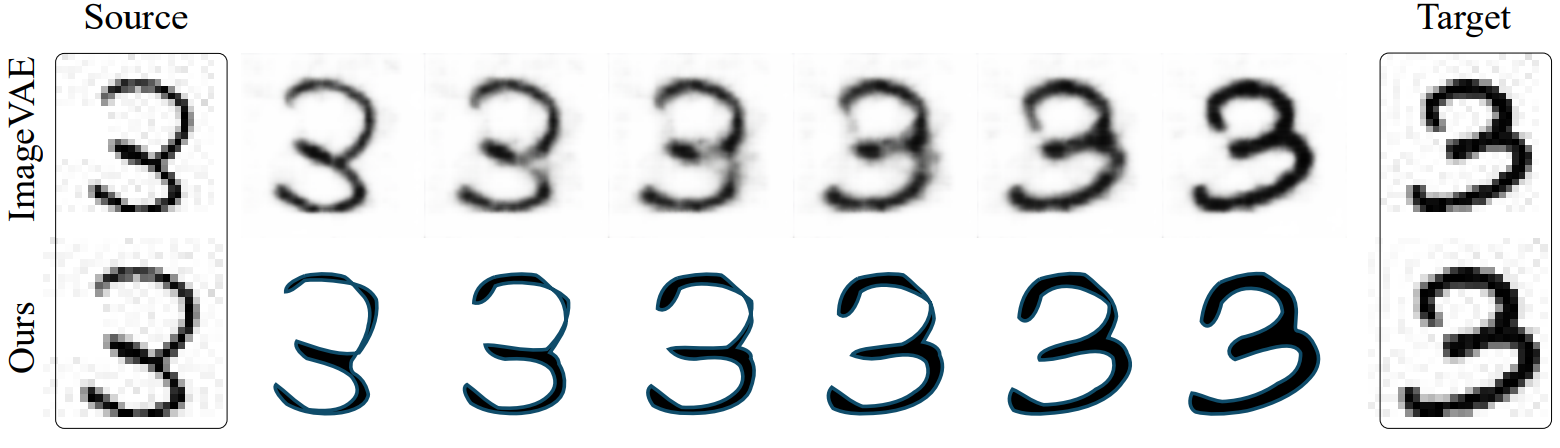
Our model produces vector outputs, while ImageVAE is limited to low-resolution raster images
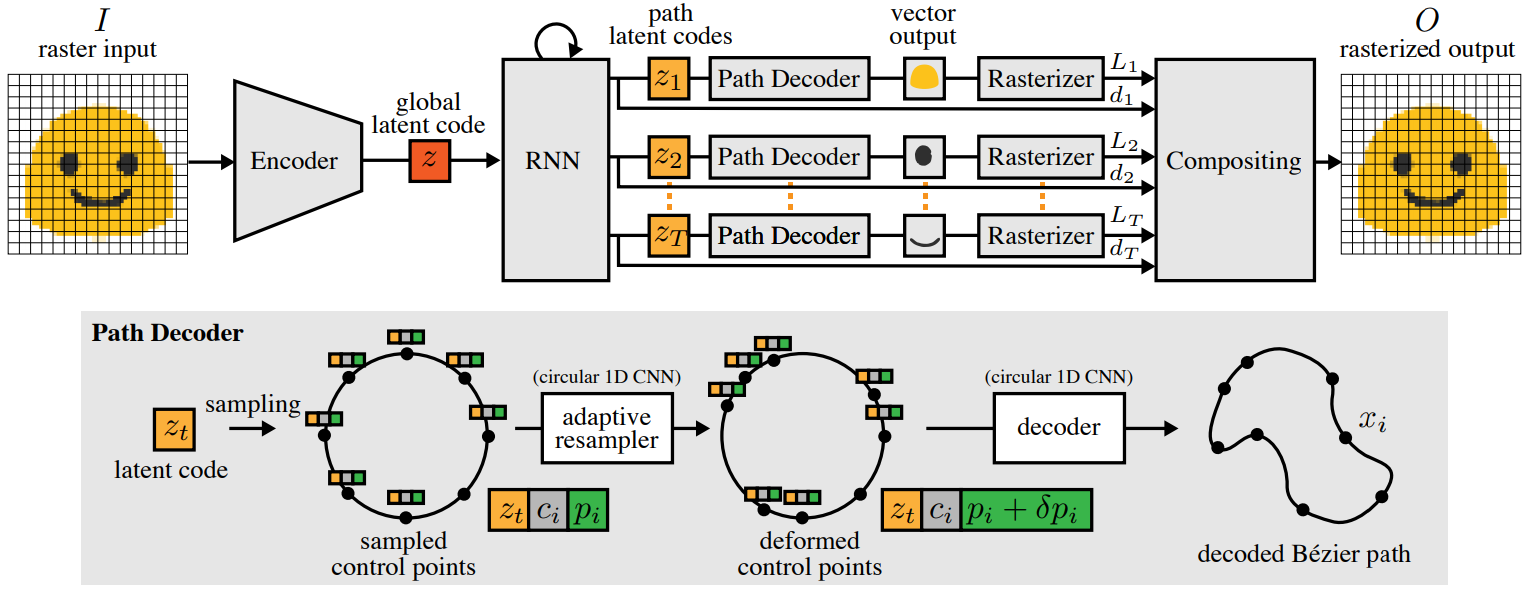
Architecture Overview
We train an end-to-end variational autoencoder that encodes a raster image to a latent code z, which is then decoded to a set of ordered closed vector paths (top). We then rasterize the paths using DiffVG and composite them together using DiffComp to obtain a rasterized output, which we compare to the ground truth raster target for supervision at training time. Our model can handle graphics with multiple component paths. It uses an RNN to produce a latent code zt for each path, from the global latent code z representing the graphic as a whole. Our path decoder (bottom) decodes the path codes into closed Bezier paths. Our representation ensures the paths are closed by sampling the path ´ control points uniformly on the unit circle. These control positions are then deformed using a 1D convolutional network with circular boundary conditions to enable adaptive control over the point density. Finally, another 1D circular CNN processes the adjusted points on the circle to output the final path control points in the absolute coordinate system of the drawing canvas. The auxiliary network that predicts the optimal number of control points per path is trained independently from our main model; it is not shown here.
Variable Sampling
Our decoder provides a natural control over the complexity of the vector graphics it produces. By adjusting the sampling density on the unit circle, we can increase the number of Bezier segments and obtain a finer or vector representation of a target raster image. Our adaptive sampling mechanism improves reconstruction accuracy, compared to a uniform distribution of the control points with the same number of segments

Latent space correspondences
Im2Vec encodes shapes as deformation of a topological disk. This naturally gives a point-to-point correspondence between shapes across graphics design once we encode them in our latent space. Graphics can be made of a single path (top), or multiple paths (bottom). In both cases, our model establish meaningful geometric correspondences between the designs, indicated by the blue–orange color coding.

Bibtex
@misc{reddy2021im2vec,
title={Im2Vec: Synthesizing Vector Graphics without Vector Supervision},
author={Pradyumna Reddy and Michael Gharbi and Michal Lukac and Niloy J. Mitra},
year={2021},
eprint={2102.02798},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Reference
Also refer to previous work on Differentiable Compositing at http://geometry.cs.ucl.ac.uk/projects/2020/diffcompositing/ and Differentiable Rasterization at https://people.csail.mit.edu/tzumao/diffvg/