Towards a Neural Graphics Pipeline for Controllable Image Generation
1CFCS, Peking University, 2University College London, 3Tel Aviv University, 4AICFVE, Beijing Film Academy, 5Adobe Research
Eurographics 2021
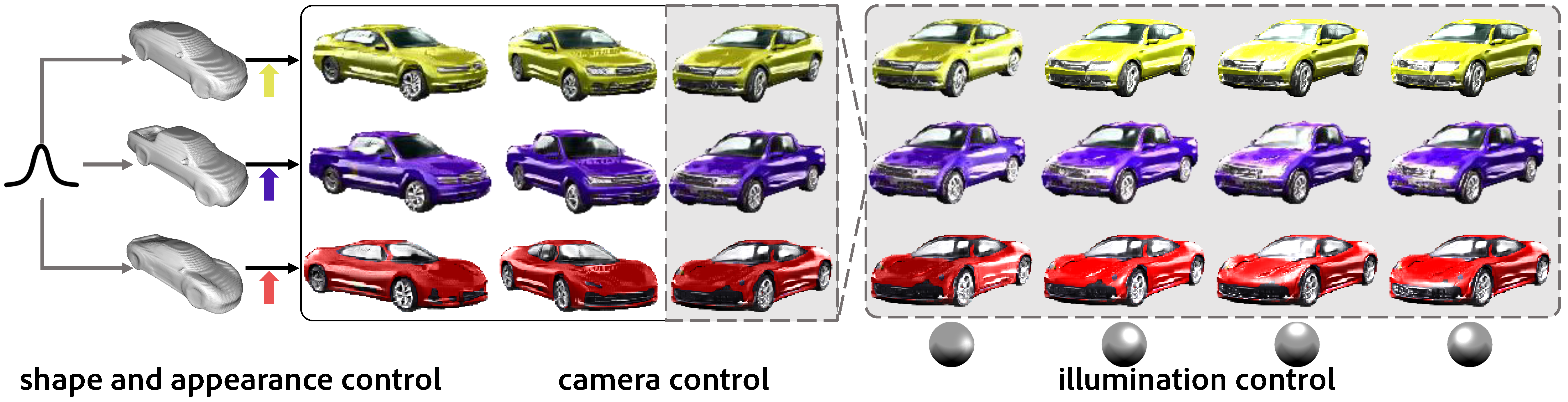 |
Neural Graphics Pipeline (NGP), a GAN-based model, samples a coarse 3D model, and provides full control over camera and illumination, and responds to geometry and appearance edits. NGP is trained directly on unlabelled real images. Mirrored balls (right-bottom) indicate corresponding illumination setting. |
Abstract
We present Neural Graphics Pipeline (NGP), a hybrid generative model that brings together neural and traditional image formation models. NGP generates coarse 3D models that are fed into neural rendering modules to produce view-specific interpretable 2D maps, which are then composited into the final output image using a traditional image formation model. Our approach offers control over image generation by providing direct handles controlling illumination and camera parameters, in addition to control over shape and appearance variations. The key challenge is to learn these controls through unsupervised training that links generated coarse 3D models with unpaired real images via neural and traditional (e.g., Blinn-Phong) rendering functions without establishing an explicit correspondence between them. We evaluate our hybrid modeling framework, compare with neural-only generation methods (namely, DCGAN, LSGAN, WGAN-GP, VON, and SRNs), report improvement in FID scores against real images, and demonstrate that NGP supports direct controls common in traditional forward rendering.
NGP at Inference Time
At test time, starting from a sampled noise vector and a set of user control signals (marked in yellow), NGP uses a combination of learned networks (marked in mustard) and fixed functions (marked in blue) to produce a range of interpretable feature maps (including four reflectance propertys maps and a realistic specular map), which are then combined to produce a final image. Please refer to the paper for more technical details.
Visual Results and Comparisons

Qualitative comparison with baseline methods. NGP versus DCGAN, LSGAN, WGANGP, and VON. All the models were trained on the same set of real-world images.
Controllable Image Generation
Shape control. NGP generates images of diverse shapes with ease via simply changing the shape code. Additionally, the user can directly edit the coarse geometry, as shown in the main video.
Illumination control. Our method models detailed normal maps in the reflectance property maps generation stage, so that additional lights can be added on top with explicit control of the illumination. We call this more versatile option NGP-plus (see details in Sec. A.5). Such level of control (i.e., explicit light count, position, and intensity) is not supported by VON and Hologan. The video above shows images generaterd with changing lights. And the lower half of the figure below shows the effect of generating various images with different additional light settings.
Camera control. We also support full camera view control for the final generated image while keeping all other factors. The upper part of the figure below illustrates the effect of changing the camera view for generating different final images. Note that earlier works including VON, SRNs, and Hologan also support various levels of camera control.

Appearance control. The overall appearance, particularly the colorization, of the content in the generated images can be easily changed by providing an exemplar image as guidance, leading to controllable and various appearance in generated images (see the figure below, note that the specular highlights on the surface are preserved even under changes to the color of the cars/chairs.). Further, this allows the user to simply edit the diffuse albedo, akin to traditional control, using existing imaging tools, and render the final image using NGP, thus benefiting from the appearance disentanglement.

Paper Video
Paper

References
[DCGAN] Radford Alec, Metz Luke, and Chintala Soumith. Unsupervised representation learning with deep convolutional generative adversarial networks. In International Conference on Learning Representations (ICLR), 2016.
[LSGAN] Xudong Mao, Qing Li, Haoran Xie, Raymond YK Lau, Zhen Wang, and Stephen Paul Smolley. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, pages 2794–2802, 2017.
[WGAN-GP] Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron Courville. Improved training of wasserstein gans. In Advances in Neural Information Processing Systems (NeurIPS), 2017.
[VON] Jun-Yan Zhu, Zhoutong Zhang, Chengkai Zhang, Jiajun Wu, Antonio Torralba, Josh Tenenbaum, and Bill Freeman. Visual object networks: image generation with disentangled 3d representations. In Advances in Neural Information Processing Systems (NeurIPS), pages 118–129, 2018.
[SRNs] Vincent Sitzmann, Michael Zollhöfer, and Gordon Wetzstein. Scene representation networks: Continuous 3d-structure-aware neural scene representations. In Advances in Neural Information Processing Systems (NeurIPS), pages 1119–1130, 2019.
Code
[Coming soon]
BibTex
@article{chen2021ngp,
title = {Towards a Neural Graphics Pipeline for Controllable Image Generation},
author = {Xuelin Chen and Daniel Cohen-Or and Baoquan Chen and Niloy J. Mitra},
journal = {Computer Graphics Forum},
volume = {40},
number = {2},
year = {2021}
}