Factored Neural Representation for Scene Understanding
Yu-Shiang Wong1 Niloy J. Mitra1,2
1University College London 2Adobe Research
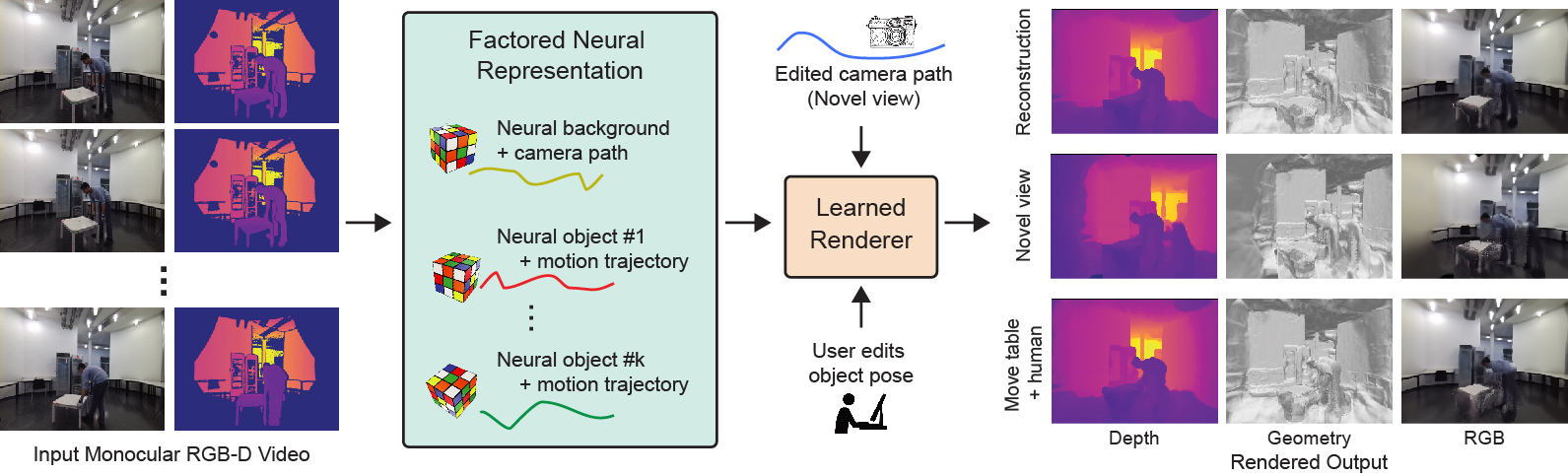
We present an algorithm that directly factorizes raw RGB-D monocular video using keyframe annotations to produce object-level neural representation with explicit motion trajectories and possibly deformation information. The decoupling subsequently enables different object manipulation and novel view synthesis applications to produce authored videos. We do not make use of any template but instead use an end-to-end optimization to enable factorization. Note that the human deforms/moves in this sequence.
Dynamic Scene Reconstruction - Synthetic Data
We develop a new dataset using publicly available CAD models from ShapeNet and inject non-rigid motion from the DeformingThings4D dataset.
Our synthetic data is rendered using Blender through the well-developed Kubric and Bpycv toolkits.
We test our system and demonstrate its reconstruction results.
Scene Reconstruction (Training Cameras)
Here we compare our object factorization results.
Please use mouse dragging to browse results.
For the comparisons (iMap and Nice-SLAM), we use depth order to generate the composed full-scene results.
Display items:
Input RGB-D |
Our Reconstruction |
Per-object training + MLP (iMap) |
Per-object training + Multi-reso. Grids (NiceSLAM) |
Scene Reconstruction (Validation Cameras)
Here we show the reconstruction results using the validation cameras.
Display items:
Input RGB-D |
Our Reconstruction |
Per-object training + MLP (iMap) |
Per-object training + Multi-reso. Grids (NiceSLAM) |
Object Reconstruction (Training Cameras)
Here we compare our object factorization results. Please use mouse dragging to browse results.
Display items:
Input RGB and Inferred Segmentation |
Our Reconstruction |
Per-object training + MLP (iMap) |
Per-object training + Multi-reso. Grids (NiceSLAM) |
Object Reconstruction (Validation Cameras)
Here we compare our object factorization results. Please use mouse dragging to browse results.
Display items:
Input RGB and Inferred Segmentation |
Our Reconstruction |
Per-object training + MLP (iMap) |
Per-object training + Multi-reso. Grids (NiceSLAM) |
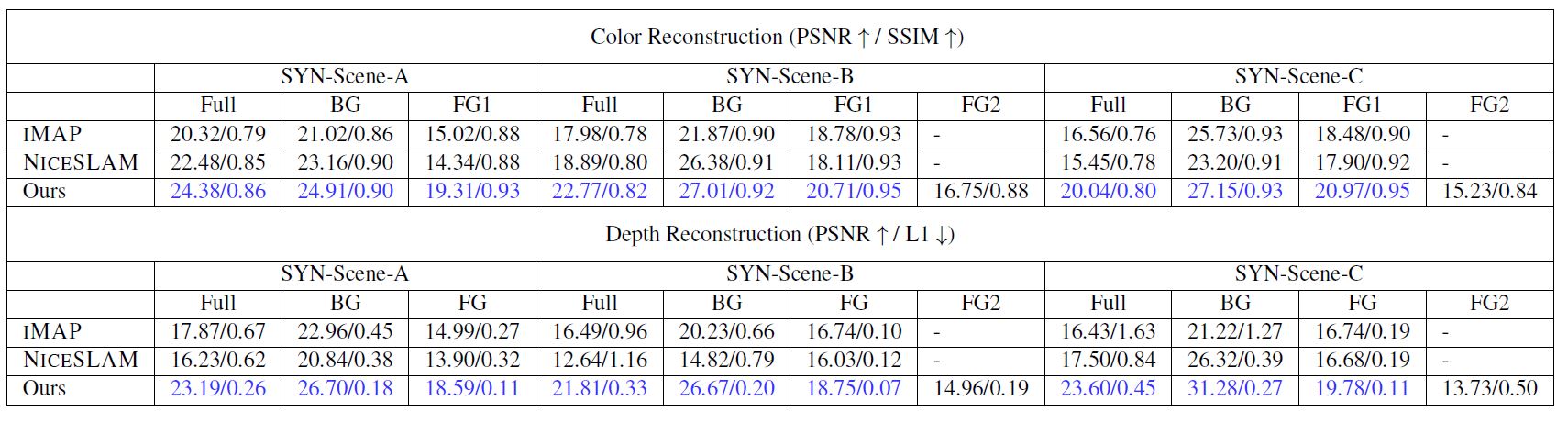
Quantitative Evaluation on Our Synthetic Dataset
(Top/Bottom) Quantitative color/depth novel view rendering results on validation cameras. Ours largely produces better reconstruction, validating that our joint optimization captures better scene geometry.
Dynamic Scene Reconstruction - Real-world Data
We also test on real RGB-D monocular captures using the camera \(k_0\) in the BeHave dataset.
Scene Reconstruction (Training Cameras)
Here we compare our object factorization results. For the comparisons (iMap and Nice-SLAM), we use depth order to generate the composed full-scene results. Please use mouse dragging to browse results.
Display items:
Input RGB-D |
Our Reconstruction |
Per-object training + MLP (iMap) |
Per-object training + Multi-reso. Grids (NiceSLAM) |
Object Reconstruction
Here we compare our object factorization results. Please use mouse dragging to browse results.
Display items:
Input RGB and Inferred Segmentation |
Our Reconstruction |
Per-object training + MLP (iMap) |
Per-object training + Multi-reso. Grids (NiceSLAM) |
Method
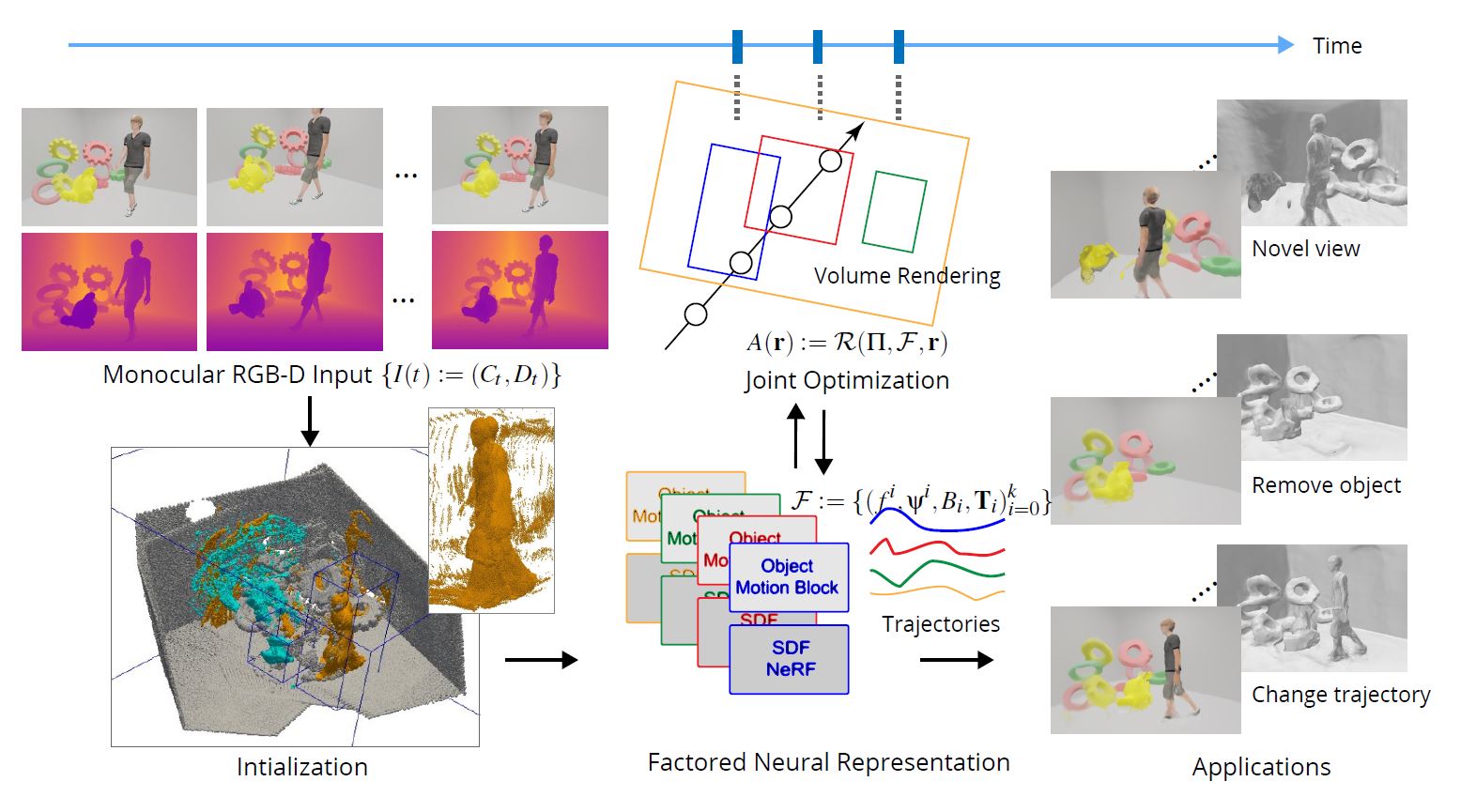
Starting from a monocular RGB-D sequence \(\{I(t)\}\), we extract a \(\textbf{factored neural representation}\) \(\mathcal{F}\) that contains separate neural models for the background and each of the moving objects along with their trajectories. For any object tagged as \(\textit{nonrigid}\), we also optimize a corresponding deformation block (e.g., human). First, in an initialization phase, We assume access to keyframe annotation (segmentation and AABBs) over time, propagate them to neighboring frames via dense visual tracking and optical flow, and estimate object trajectories. Then, we perform end-to-end optimization using a customized neural volume rendering block. The factored representation enables a variety of applications involving novel view synthesis and object manipulations.
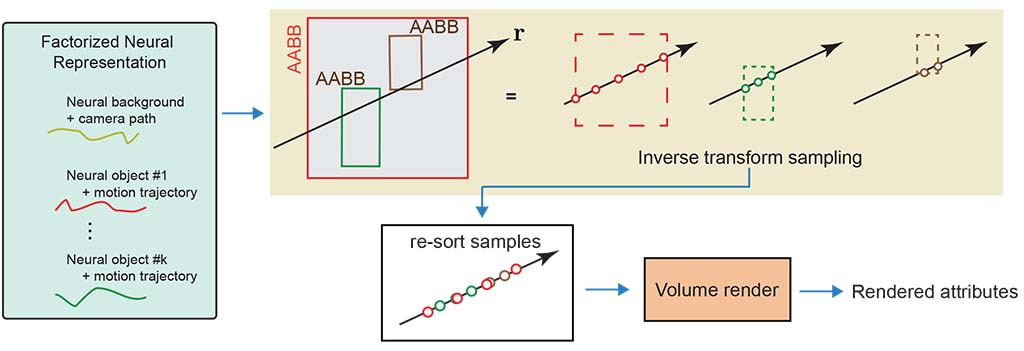
Given a factored representation \( F(t)\) and any query ray \(r\) from the current camera, we first intersect each objects' bounding box \(B_i\) to obtain a sampling range and then compute an uniform sampling for each of the intervals. For each such sample \(s\), we lookup feature attributes by re-indexing using local coordinate \(T_i^{-1} s \), resort the samples across the different objects based on (sample) depth values, and then volume render to get a rendered attribute. Background is modeled as the 0-th object. For objects with active \(\textit{non-rigid}\) flags, we also invoke the corresponding deformation block. The neural representations and the volume rendering functions are jointly trained.
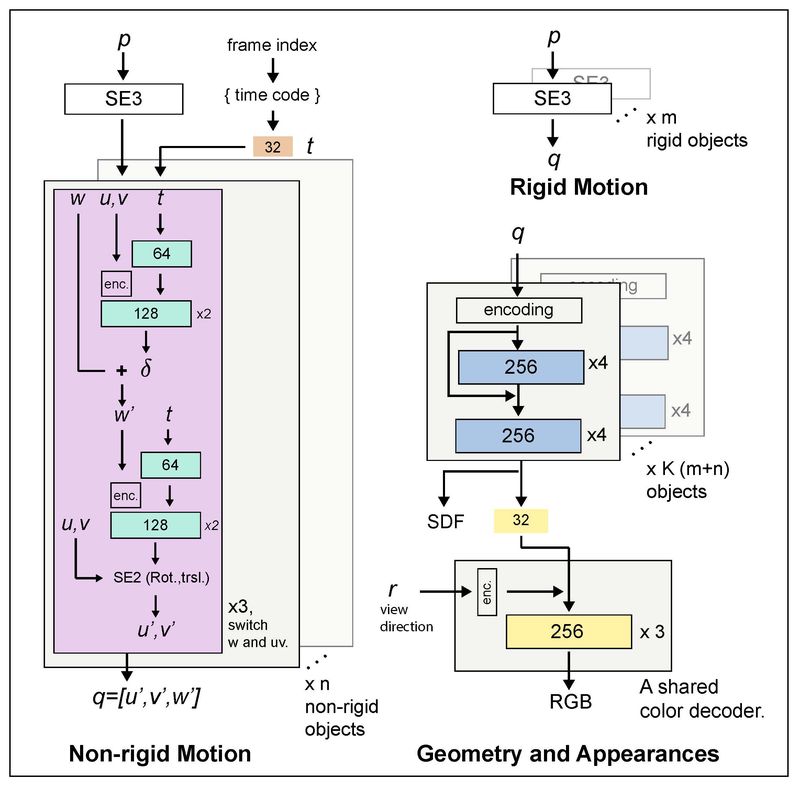
We provide our network architecture below. For the SDF MLP networks, we use geometric initialization, weighted normalization, Softplus activations, and a skip-connection at the 4-th layer. The input coordinates and view directions are lifted to a high dimensional space using positional encoding. For rigid objects, we use \(\mathbb{SE}3\) representation, \ie a quaternion and a translation vector. For non-rigid objects, we use bijective deformation blocks proposed by Cai et. al. with weighted normalization and Softplus activations as well. For the color MLP network, we use ReLU activation.
Bibtex
@article{,
title={Factored Neural Representation for Scene Understanding},
author={Wong, Yu-Shiang and Mitra, Niloy},
journal={arXiv preprint arXiv:},
year={2023}
}