
Some Segmentation Results on PartNet
While PointNet++ struggles to detect accurately the boundaries between different parts, our deep architecture performs a much finer segmentation in those frontier areas.
University College London
CVPR 2020
In this work we train deeper and more accurate networks by introducing three point processing blocks that improve accuracy and memory consumption: a convolution-type block for point sets that blends neighborhood information in a memory-efficient manner; a multi-resolution point cloud processing block; and a crosslink block that efficiently shares information across low- and high-resolution processing branches. By combining these blocks, we design significantly wider and deeper architectures. We extensively evaluate the proposed architectures on multiple point segmentation benchmarks (ShapeNet-Part, ScanNet, PartNet). We report systematic accuracy and memory consumption improvements by using our generic modules in conjunction with multiple architectures (PointNet++, DGCNN, SpiderNet, PointCNN). All of our code are publicly available.
In this work, we enhance such point processing networks that replicate local neighborhood information by introducing a set of modules that improve memory footprint and accuracy, without compromising on inference speed. We call the resulting architectures Lean Point Networks, to highlight their lightweight memory budget. We build on the decreased memory budget to go deeper with point networks. As has been witnessed repeatedly in the image domain, we show that going deep also increases the prediction accuracy of point networks.
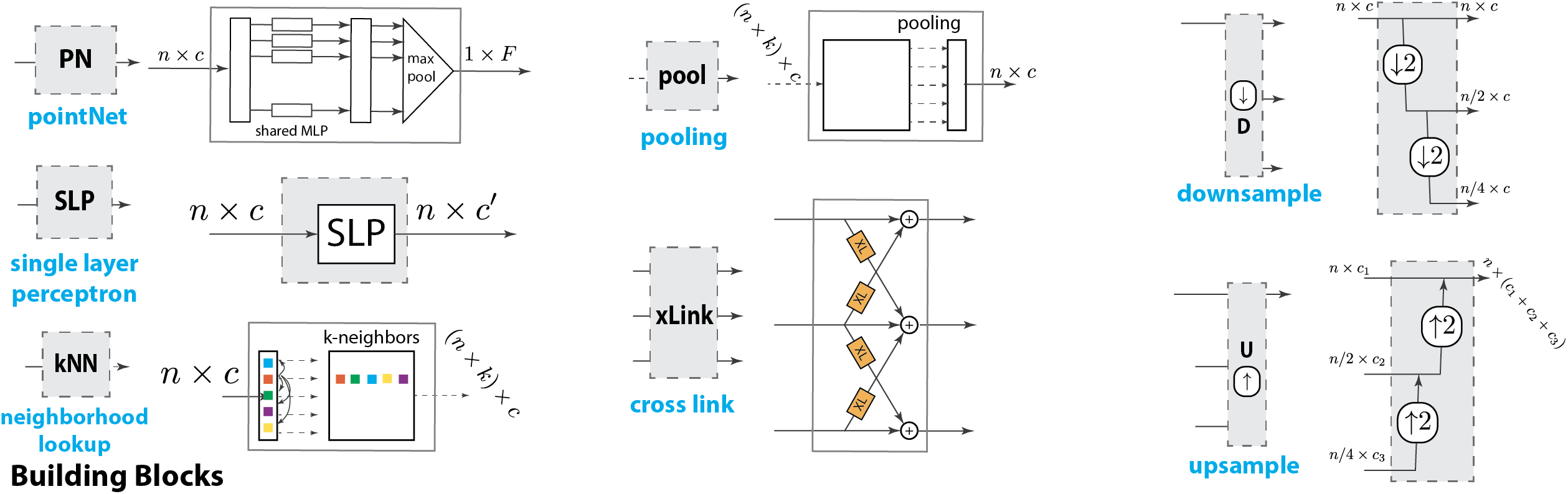
Apart from standard neighborhood lookup, pooling and SLP layers, we introduce cross-link layers across scales, and propose multi-resolution up/down sampling blocks for point processing. PointNet module combines a stack of shared SLP (forming an MLP) to lift individual points to higher dimensional features and then performs permutation-invariant local pooling.

The standard PN++ layer in (a) amounts to the composition of a neighborhood-based lookup and a PointNet element. In (b) we propose to combine parallel PointNet++ blocks in a multi-resolution architecture, and in (c) allow information to flow across branches of different resolutions through a cross-link element. In (d) we propose to turn the lookup-SLP-pooling cascade into a low-memory counterpart by removing the kNN elements from memory once computed; we also introduce residual links, improving the gradient flow. In (e) we stack the block in (d) to grow in depth and build our deep architecture. Each of these tweaks to the original architecture allows for systematic gains in memory and computational efficiency. The green box indicates that the block can be grown in depth by stacking those green units.
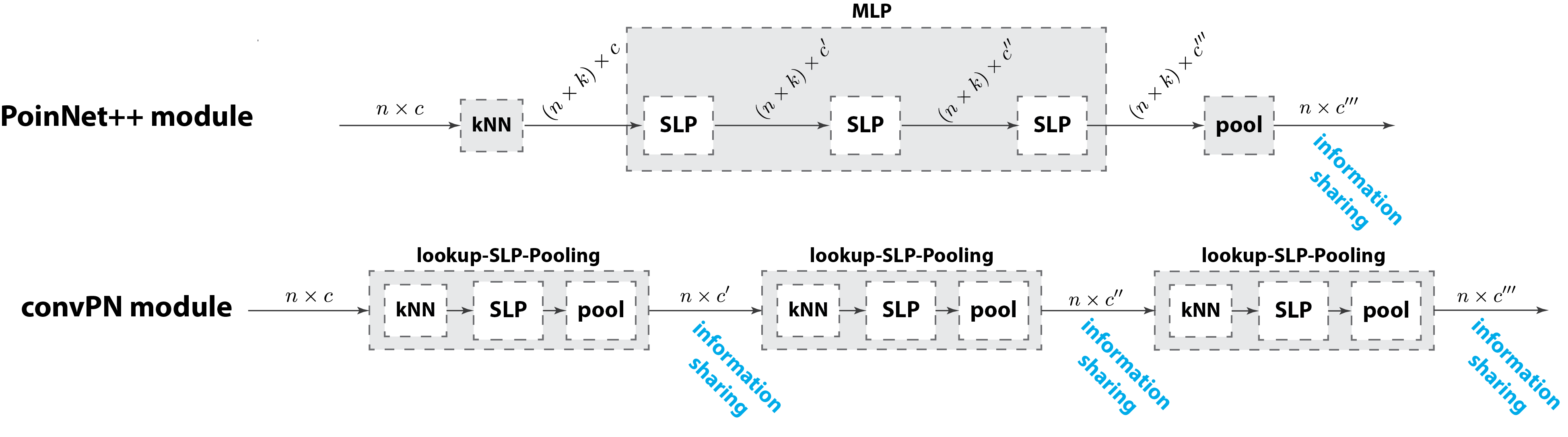
The convPN module replaces the MLP with its pooling layer by a sequence of SLP-Pooling modules which has two benefits (i) memory savings as the layer activations are saved only through the pooled features and (ii) better information flow as it increases the frequency at which neighbors share information. This design requires however to do neighborhood lookups back again in-between the layers
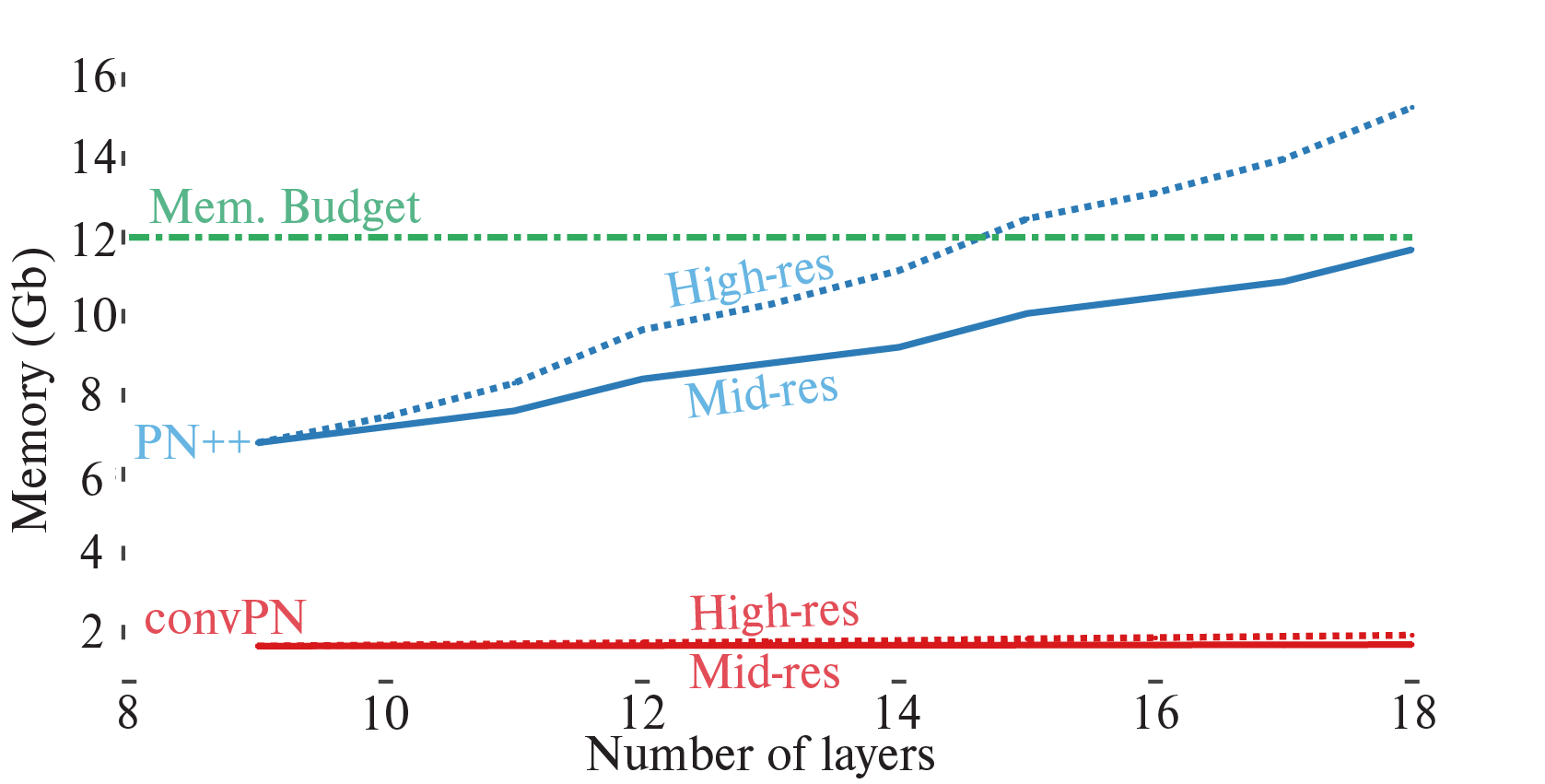
This new design allows drastic memory savings: doubling the number of layers for convPN results only in an increase in memory by +2.3% and+16.8% for mid- and high- resolution respectively, which favorably compares to the +72% and +125% increases for PointNet++
While PointNet++ struggles to detect accurately the boundaries between different parts, our deep architecture performs a much finer segmentation in those frontier areas.
@inproceedings{le2020deeperleanpn,
title={Going Deeper with Lean Point Networks},
author={Lê, Eric-Tuan and Kokkinos, Iasonas and Mitra, Niloy J.},
booktitle={The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}
month={June},
year={2020}
}