Learning on the Edge: Investigating Boundary Filters in CNNs
- Carlo Innamorati
- Tobias Ritschel
- Tim Weyrich
- Niloy J. Mitra
University College London
International Journal of Computer Vision 2019
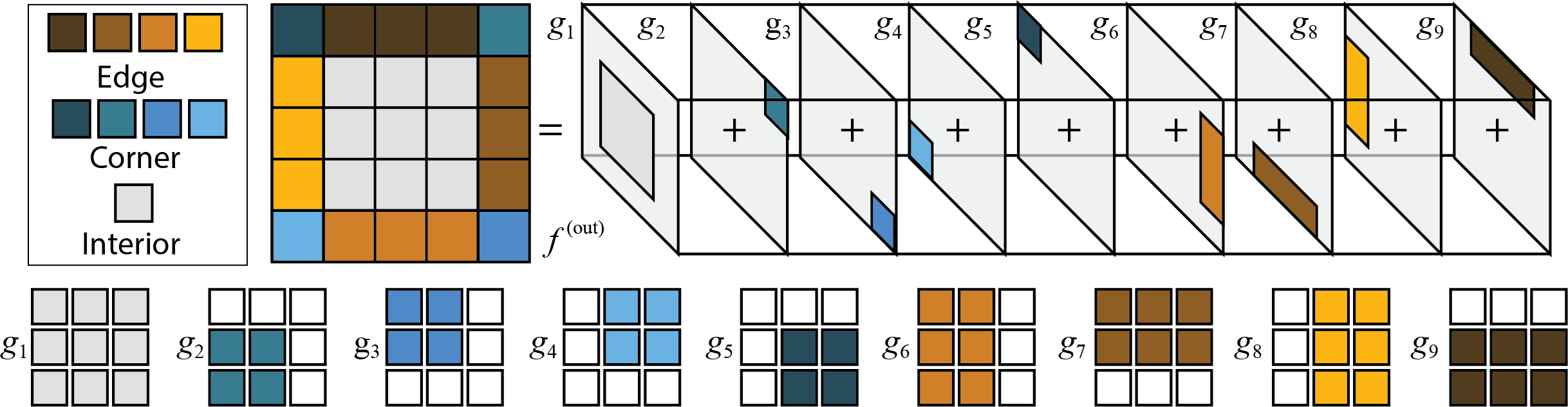
Abstract
Convolutional neural networks (CNNs) handle the case where filters extend beyond the image boundary using several heuristics, such as zero, repeat or mean padding. These schemes are applied in an ad-hoc fashion and, being weakly related to the image content and oblivious of the target task, result in low output quality at the boundary. In this paper, we propose a simple and effective improvement that learns the boundary handling itself. At training-time, the network is provided witha separate set of explicit boundary filters. At testing-time, we use these filters which have learned to extrapolate features at the boundary in an optimal way for the specific task. Our extensive evaluation, over a wide range of architectural changes (variations of layers, feature channels, or both), shows how the explicit filters result in improved boundary handling. Furthermore, we investigate the efficacy of variations of such boundary filters with respect to convergence speedand accuracy. Finally, we demonstrate an improvement of 5–20% across the board of typical CNN applications (colorization, de-Bayering, optical flow, disparity estimation, and super-resolution).
A common problem in CNN based solutions

Applying a feature detection-like filter (a) to an image with different boundary rules (b-f). We show the error as the ratio of the ideal and the observed response. A bright value means a low error due to a ratio of 1, i.e. the response is similar to the ideal condition. Darker values indicate a deterioration.
Experiments
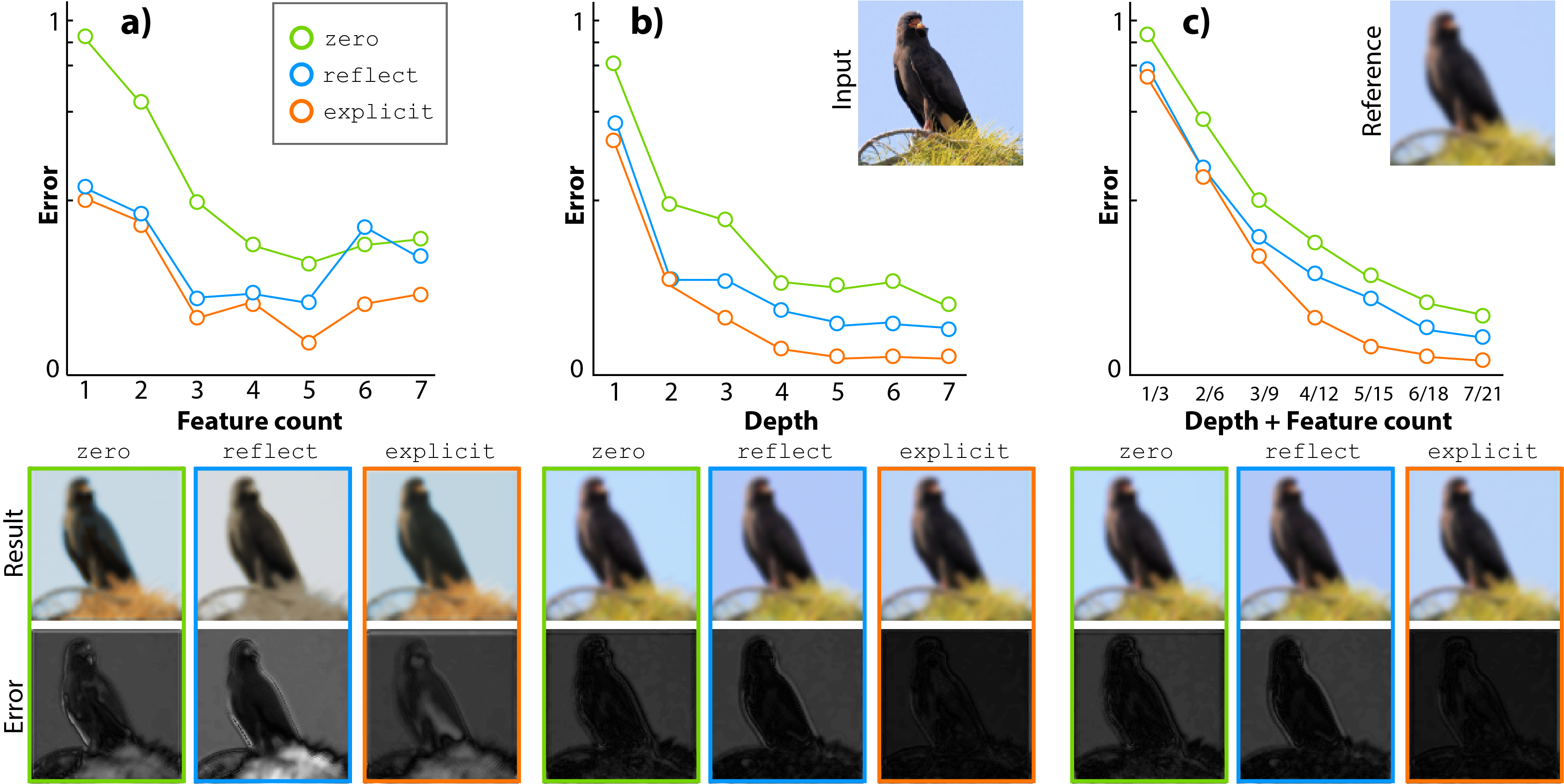
Analysis of different architectural choices using different boundary handling (colors). First, (a) we increase feature channel count (first plot and columns of insets). The vertical axis shows log error for the MSE (our loss) and the horizontal axis different operational points. Second (b), depth of the network is increased (second plot and first 4 columns of insets). Third, (c) both are increased jointly. The second row of insets shows the best (most similar to a reference) result for each boundary method (column) across the variation of one architectural parameter for a random image patch (input an reference result seen in corner).
Results
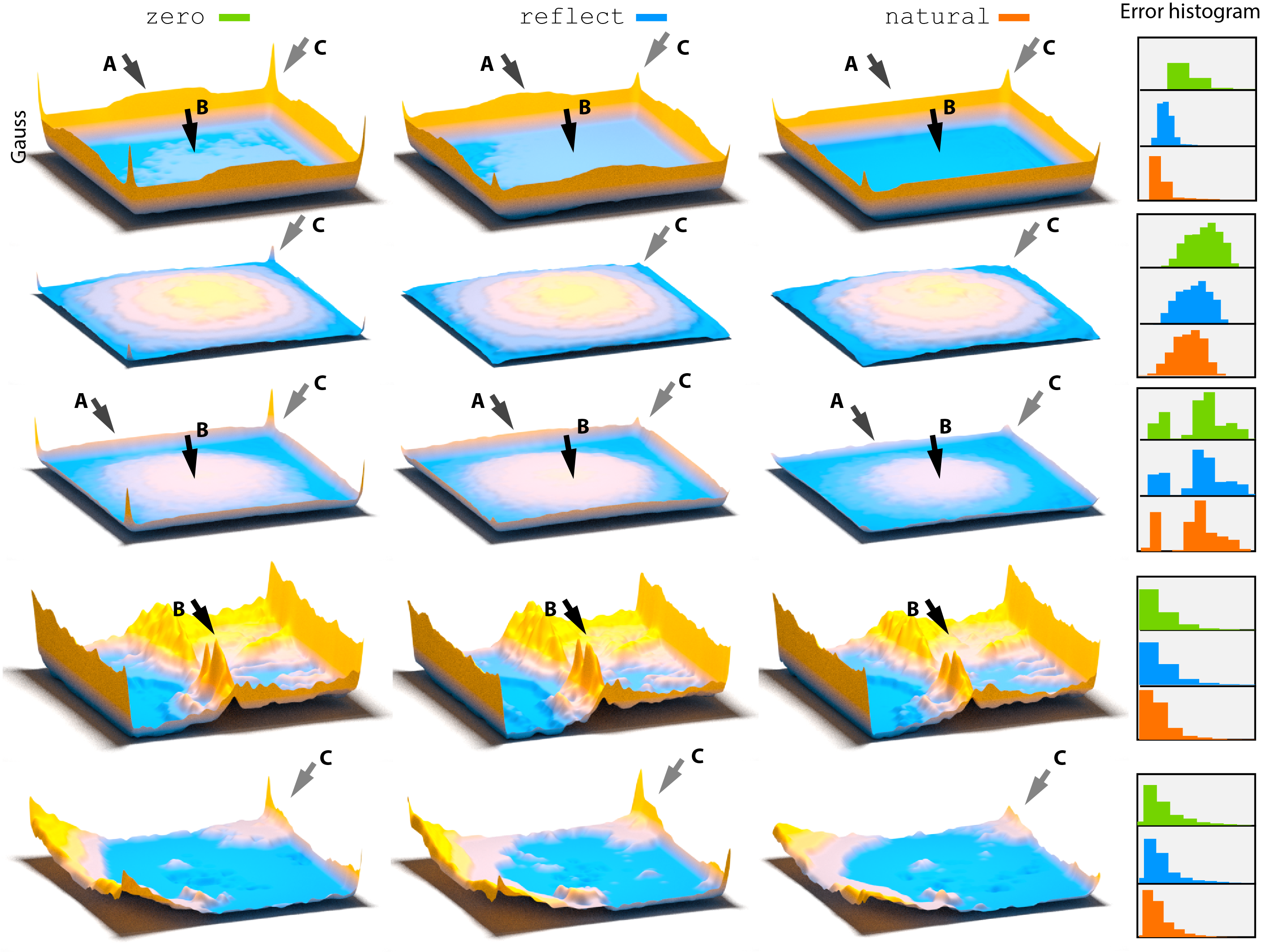
Mean errors across the corpus visualized as height fields for different tasks and different methods. Each row corresponds to one task each column to one way of handling the boundary. Arrow A marks the edge that differs (ours has no bump on the edge). Arrow B mark the interior that differs (ours is flat and blue, others is non-zero, indicting we improve also inside). Arrow C shows corners, that are consistently lower for us.
Bibtex
Acknowledgements
We thank our reviewers for their helpful comments. We also thank Paul Guerrero, Aron Monszpart and Tuanfeng Yang Wang for their technical help in setting up and fixing the machines used to carry out the experiments in this work. Additionally, we thank our reviewers for their detailed and insightful comments. This work was partially funded by the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No 642841, by the ERC Starting Grant SmartGeometry (StG-2013-335373), and by the UK Engineering and Physical Sciences Research Council (grant EP/K023578/1).