Escaping Plato's Cave: 3D Shape From Adversarial Rendering
University College London
ICCV 2019

Abstract
We introduce PLATONICGAN to discover the 3D structure of an object class from an unstructured collection of 2D images, i.e. neither any relation between the images is available nor additional information about the images is known. The key idea is to train a deep neural network to generate 3D shapes which rendered to images are indistinguishable from ground truth images (for a discriminator) under various camera models (i.e. rendering layers) and camera poses. Discriminating 2D images instead of 3D shapes allows tapping into unstructured 2D photo collections instead of relying on curated (e.g., aligned, annotated, etc.) 3D data sets. To establish constraints between 2D image observation and their 3D interpretation, we suggest a family of rendering layers that are effectively differentiable. This family includes visual hull, absorption-only (akin to x-ray), and emission-absorption. We can successfully reconstruct 3D shapes from unstructured 2D images and extensively evaluate PLATONICGAN on a range of synthetic and real data sets achieving consistent improvements over baseline methods. We can also show that our method with additional 3D supervision further improves result quality and even surpasses the performance of 3D supervised methods.
Results

Visual results for 3D reconstruction of three classes (airplane, chair, rifle) from multiple views.
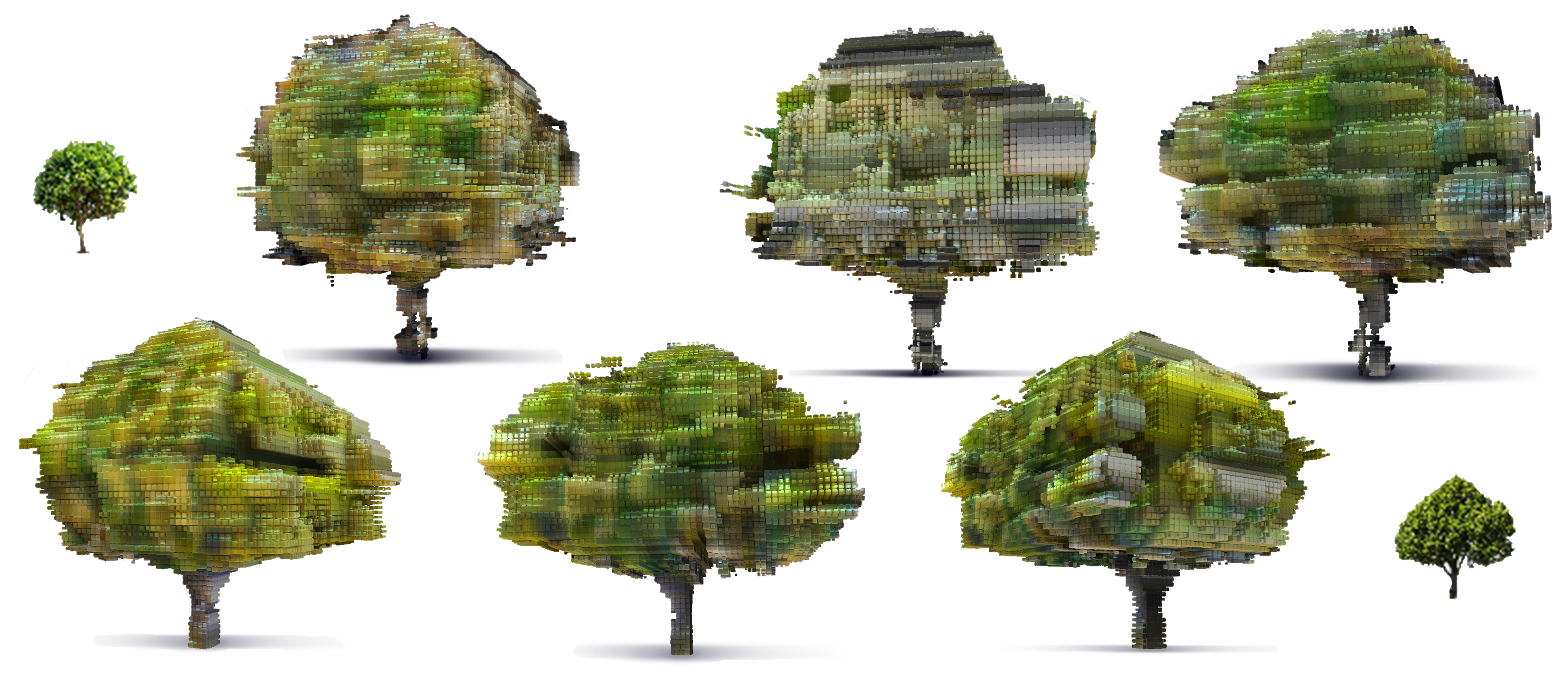
3D Reconstruction of different trees using the emissionabsorption image formation model, seen from different views (columns). The small images were used as input. We see that PLATONICGAN has understood the 3D structure, including a distinctly colored stem, fractal geometry and structured leave textures.
Errata
Thanks to Pengsheng Guo (mail) for pointing out that we had a slightly incorrect chamfer distance error metric. When calculating the chamfer distance we did not invert the binary target voxels (target = 1 - target) before calling scipy.ndimage.distance_transform_edt which returns the distance to the closest background (not the foreground) element. Thus, we have corrected the error calculation, see code and also updated Tbl. 2 in this updated arxiv version. (For comparison, the see the previous version). Note, conclusions remain unaffected.
Bibtex
@inproceedings{henzler2019platonicgan,
title={Escaping Plato's Cave: 3D Shape From Adversarial Rendering},
author={Henzler, Philipp and Mitra, Niloy J and and Ritschel, Tobias},
booktitle={Computer Vision (ICCV), 2019 IEEE International Conference on Computer Vision},
year={2019}
}