Dance In the Wild: Monocular Human Animation with Neural Dynamic Appearance Synthesis
Tuanfeng Wang1 Duygu Ceylan1 Krishna Kumar Singh1 Niloy J. Mitra1,2
1 Adobe Research 2 University College London
International Conference on 3D Vision 2021
Abstract
Synthesizing dynamic appearances of humans in motion plays a central role in applications such as AR/VR and video editing. While many recent methods have been proposed to tackle this problem, handling loose garments with complex textures and high dynamic motion still remains challenging. In this paper, we propose a video based appearance synthesis method that tackles such challenges and demonstrates high quality results for in-the-wild videos that have not been shown before. Specifically, we adopt a StyleGAN based architecture to the task of person specific video based motion retargeting. We introduce a novel motion signature that is used to modulate the generator weights to capture dynamic appearance changes as well as regularizing the single frame based pose estimates to improve temporal coherency. We evaluate our method on a set of challenging videos and show that our approach achieves state-of-the art performance both qualitatively and quantitatively.
Video
Pipeline
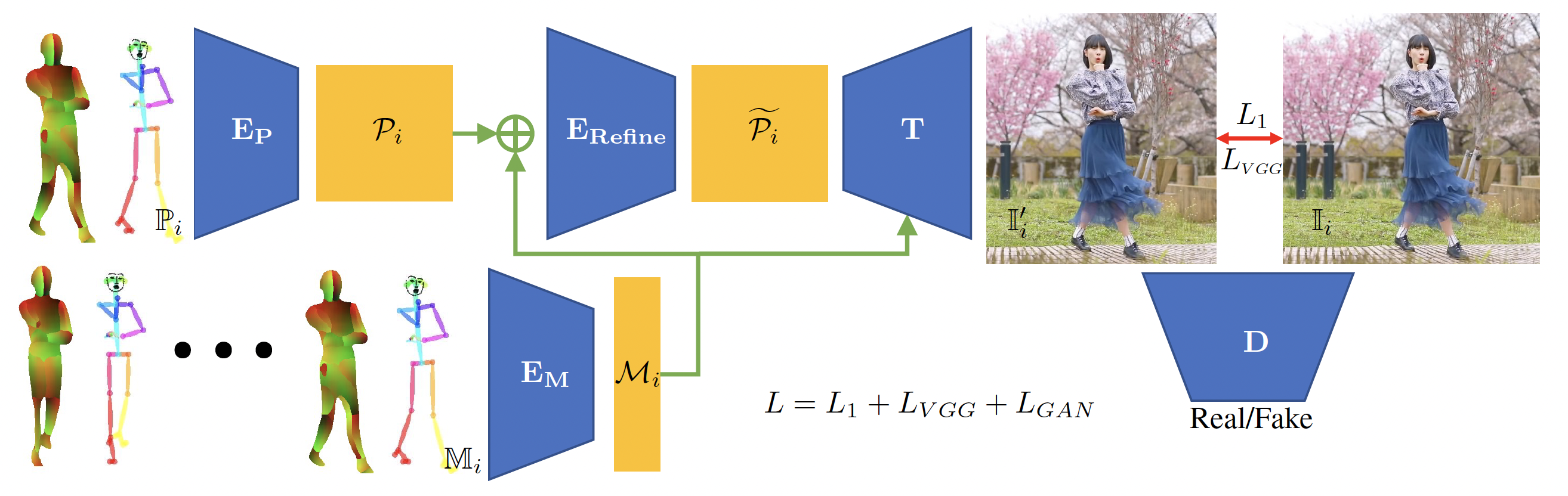
Our network takes the 2D body dense UV and keypoints as input and learns a pose feature for each frame. By concatenating the pose inputs for the past few frames, we also learn motion features. The learned motion features are used to refine the pose features to improve the temporal coherency. We synthesize the final motion-aware dynamic appearance of the character using a StyleGAN based generator conditioned on the refined pose features and modulated by the motion features.
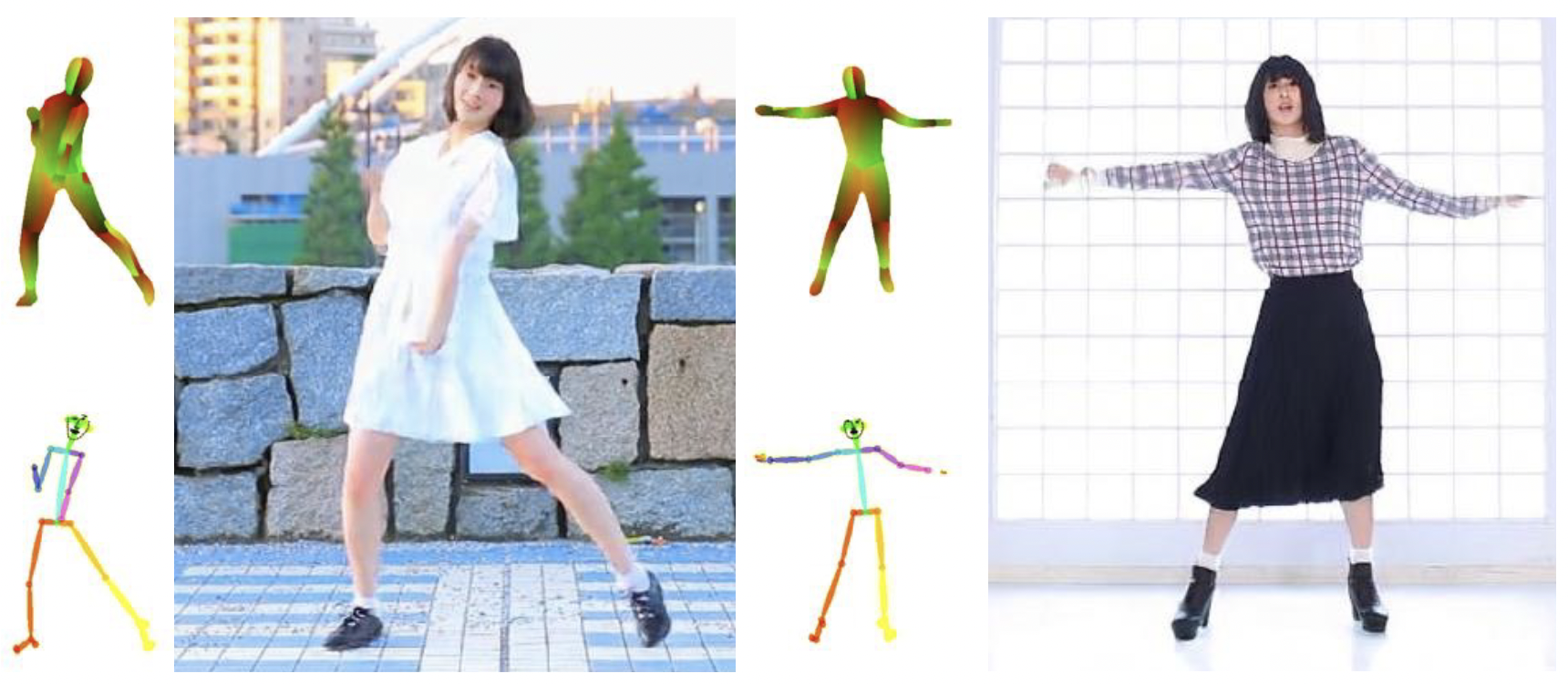
Results: Appearance Reconstruction

We train our network for character specific appearance synthesis. Here are the exemplary results on the test set for some sequences.
Application: Motion Retargeting

Our approach allows motion transfer from a source sequence to a target actor.
Bibtex
@inproceedings{
}
Acknowledgements
We would like to thank the anonymous reviewers for their constructive comments; as well as Jae Shin Yoo, Moritz Kappel, and Erika Lu for their kind help with the experiments and discussions.