Motion Guided Deep Dynamic 3D Garments
Meng Zhang1,3 Duygu Ceylan2 Niloy J. Mitra1,2
1University College London 2 Adobe Research 3 Nanjing University of Science and Technology
Siggraph Asia 2022 (conditionally accepted)
Abstract
Realistic dynamic garments on animated characters have many AR/VR applications. While authoring such dynamic garment geometry is still a challenging task, data-driven simulation provides an attractive alternative, especially if it can be controlled simply using the motion of the underlying character. In this work, we focus on motion guided dynamic 3D garments, especially for loose garments. In a data-driven setup, we first learn a generative space of plausible garment geometries. Then, we learn a mapping to this space to capture the motion dependent dynamic deformations, conditioned on the previous state of the garment as well as its relative position with respect to the underlying body. Technically, we model garment dynamics, driven using the input character motion, by predicting per-frame local displacements in a canonical state of the garment that is enriched with frame-dependent skinning weights to bring the garment to the global space. We resolve any remaining per-frame collisions by predicting residual local displacements. The resultant garment geometry is used as history to enable iterative roll-out prediction. We demonstrate plausible generalization to unseen body shapes and motion inputs, and show improvements over multiple state-of-the-art alternatives.
Method overview

We present a motion guided 3D garment prediction network that takes as input the previous state of the garment (i.e., the garment geometry, velocity, and acceleration at the previouse time t - 1) and the current body (i.e., the body geometry at current time t) and predicts the garment geometry at time t . Garment deformation is factorized into local displacements with respect to the canonical garment state, and linear skinning driven by dynamic blending weights.
Deep dynamic garment architecture
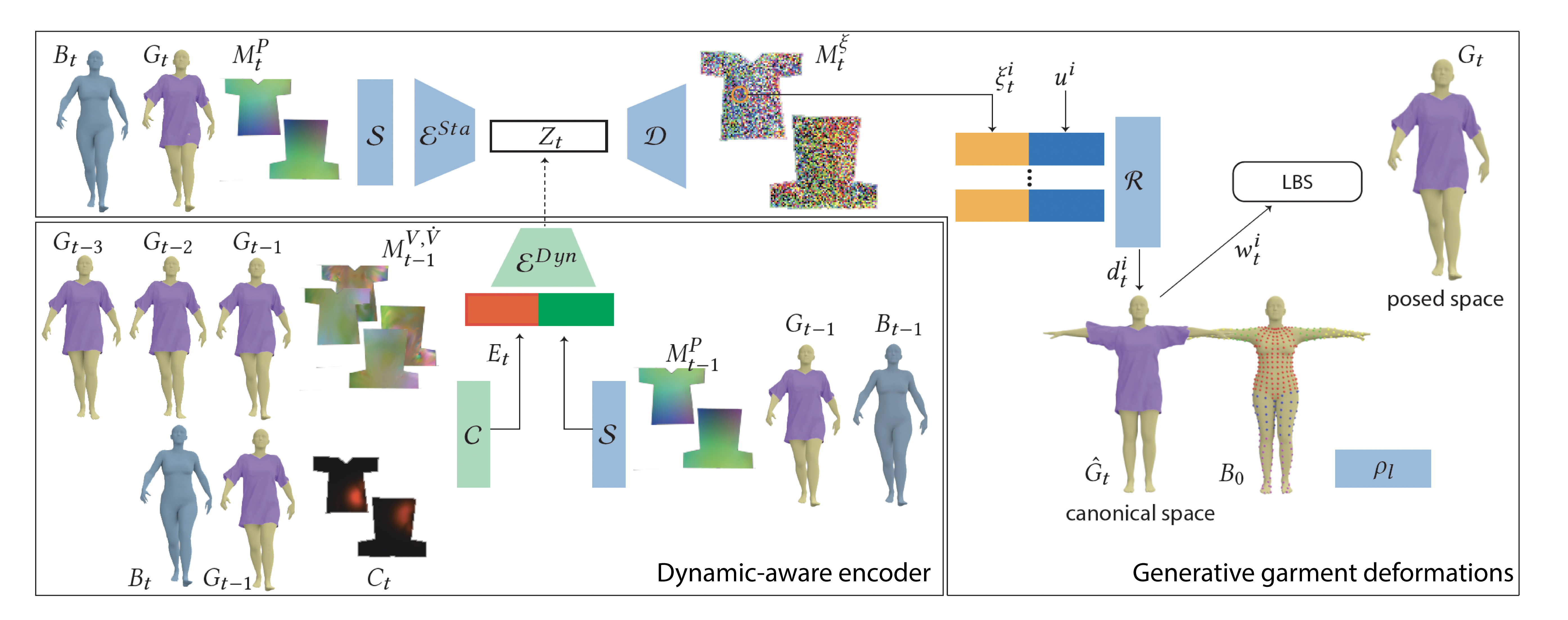
Our approach first learns a compact generative space of plausible garment deformations. We achieve this by encoding a garment geometry represented as relative to the underlying body to a latent code using a feature map encoder. A decoder then predicts a geometry feature map. We sample the feature map to obtain per-vertex geometry features. These features along with the vertex UV coordinates are provided to an MLP, to predict per-vertex canonical space displacements. We assign each vertex a skinning weight based on its proximity to the underlying body seed points weighted by a per-body part learnable kernel radius. Once a generative space of garment deformations are learned, we train a dynamic-aware encoder. We provide the previous garment geometry, the garment velocity, acceleration and the interaction between the body and the garment as input. The dynamic-aware encoder maps these inputs to a latent code in the learned deformation space which is then used to decode the current garment geometry. Blocks denoted in blue are pre-trained and kept fixed when training the blocks in green.
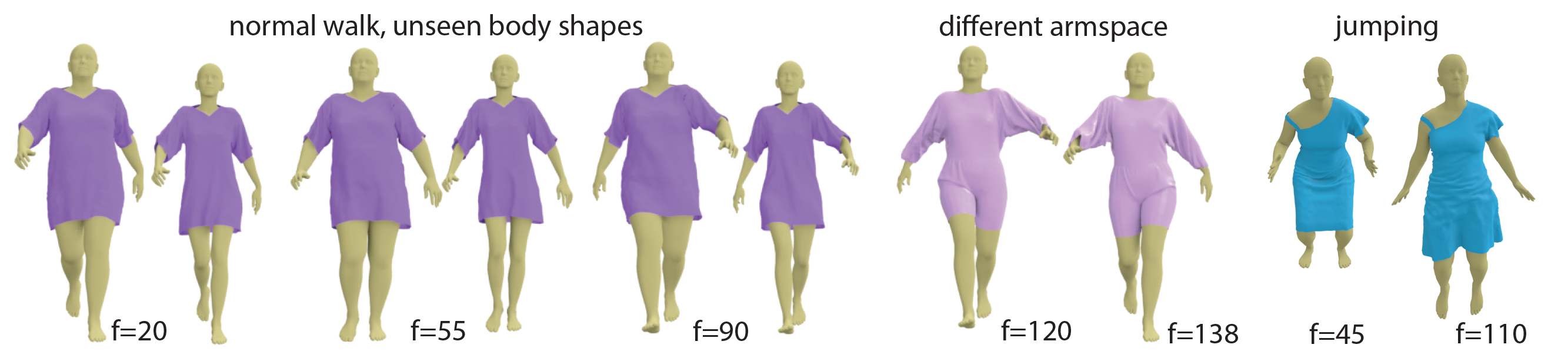
Results to show the generalization ability of our method
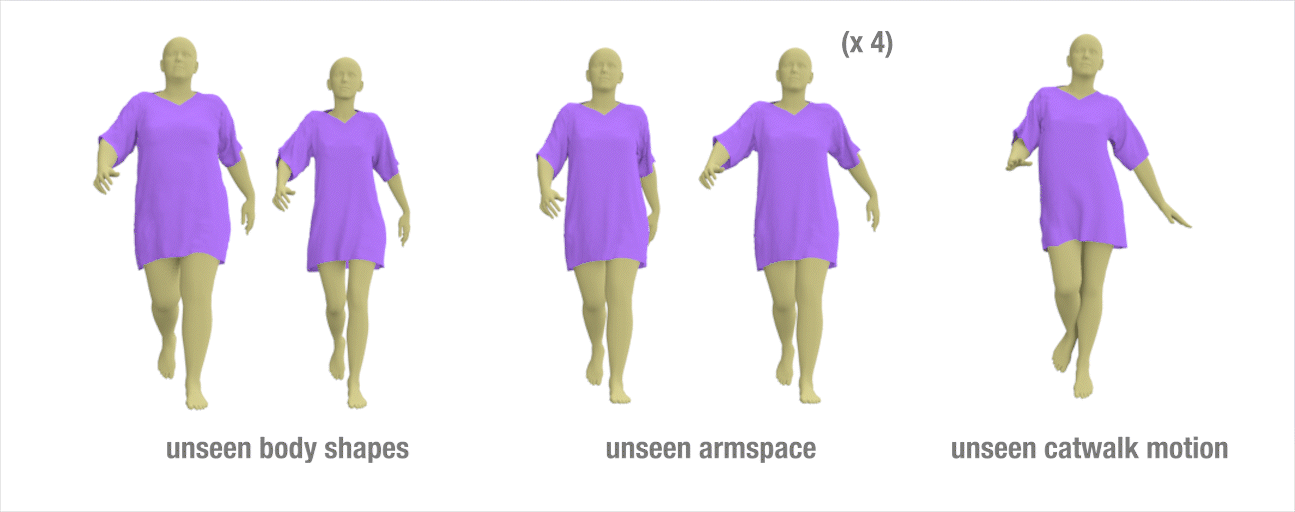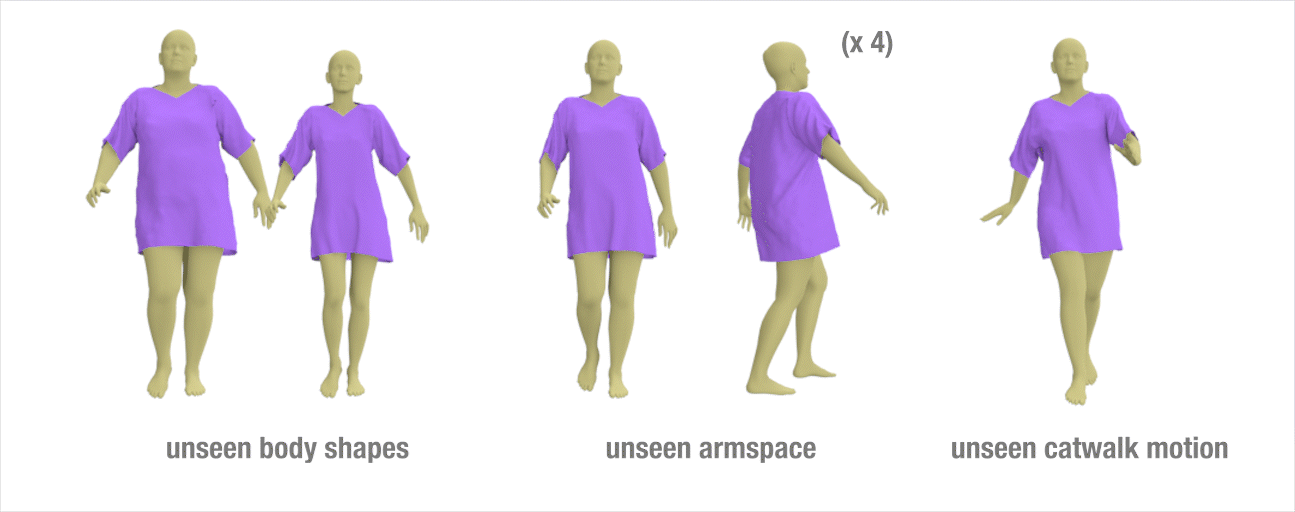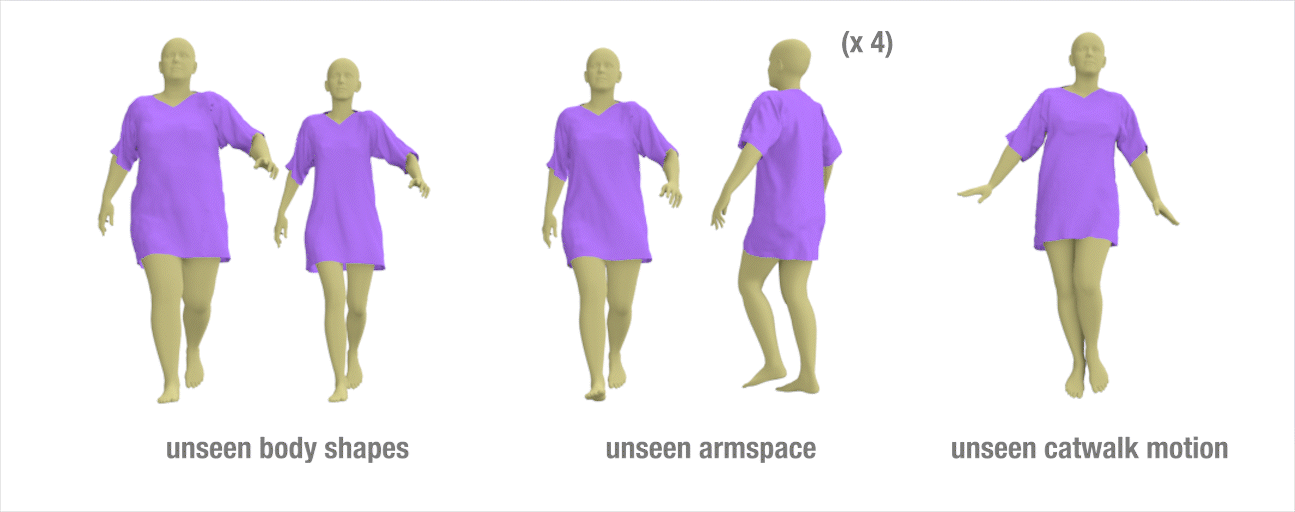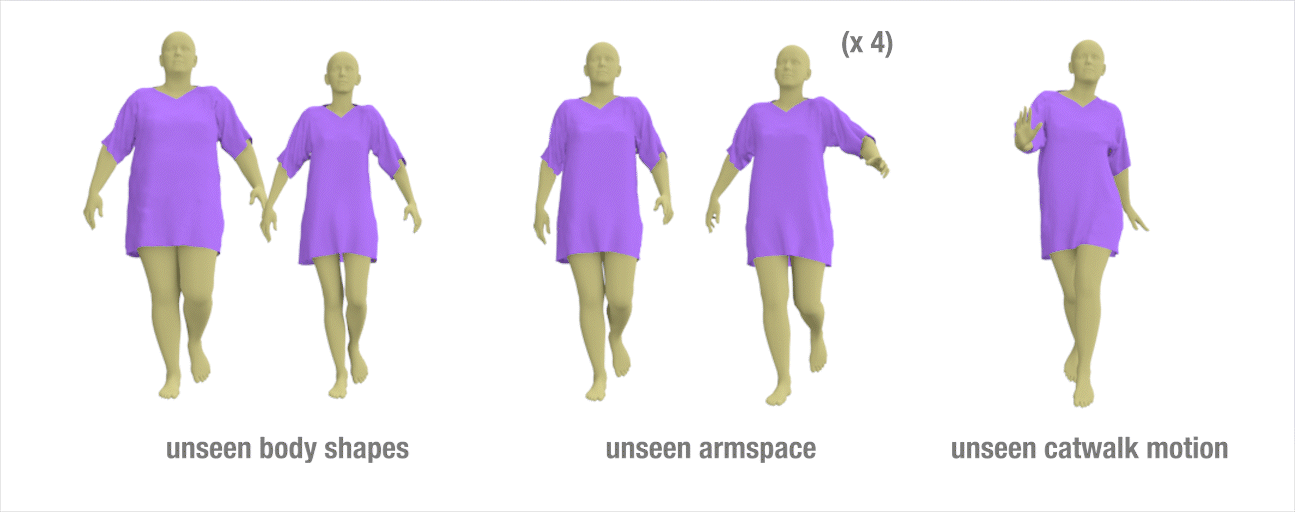

we train our network on a relatively short walking sequence of **300** frames simulated on a **fixed** body shape. Once trained, we test our method on different styles of walking motion by changing the character arm space setting, changing the speed of the motion, applying different types of walking (e.g., catwalk, strut walk), and changing the body shape.
Training of the dynamic-aware encoder

When training the dynamic-aware encoder, we enforce the constraint that when both the body and the garment preserve their states (𝐸𝑡 = 0), we should obtain the same latent code as in the previous frame. This results in capturing more accurate deformations.
Comparisons

We compare our method to the works of Santesteban et al. [2021; 2022] and PBNS [Bertiche et al. 2021a]. Our results generalize to unseen body shape (right) and capture more dynamic deformations.
Extension to layered-garments
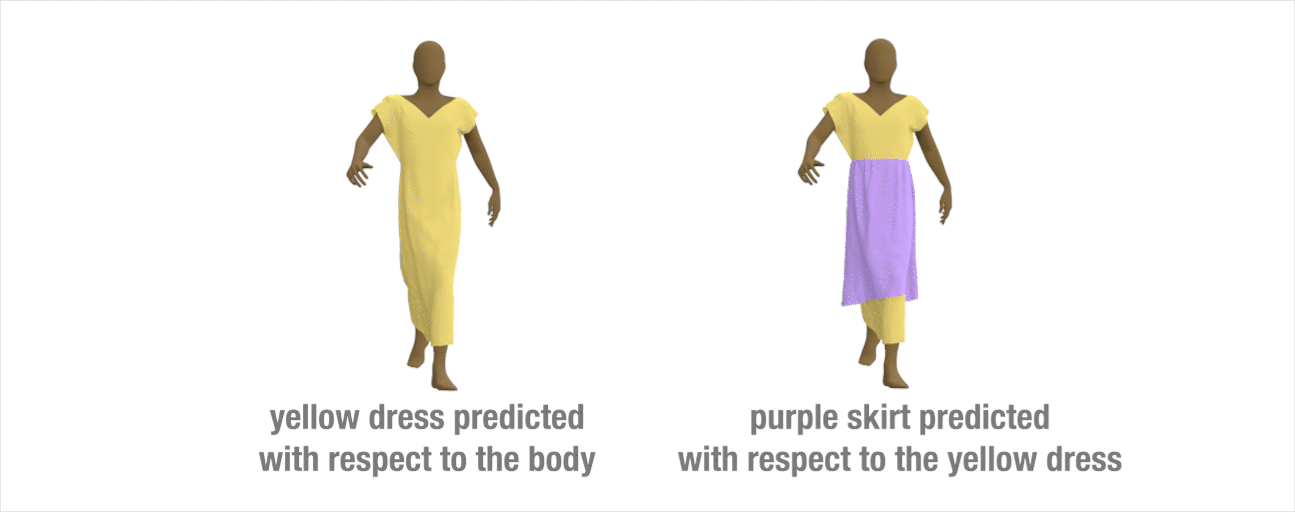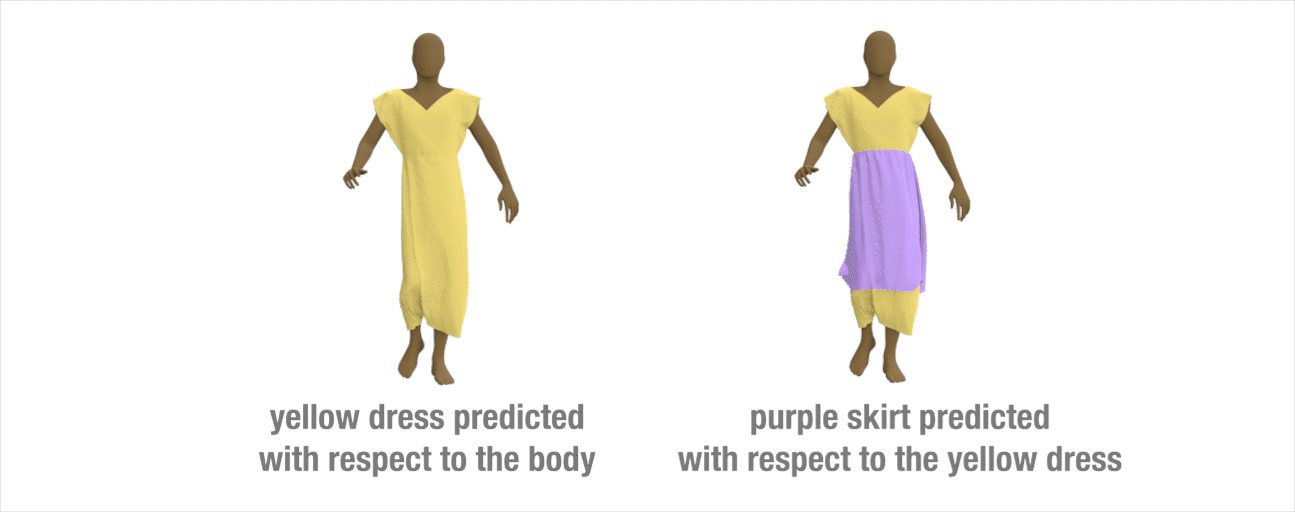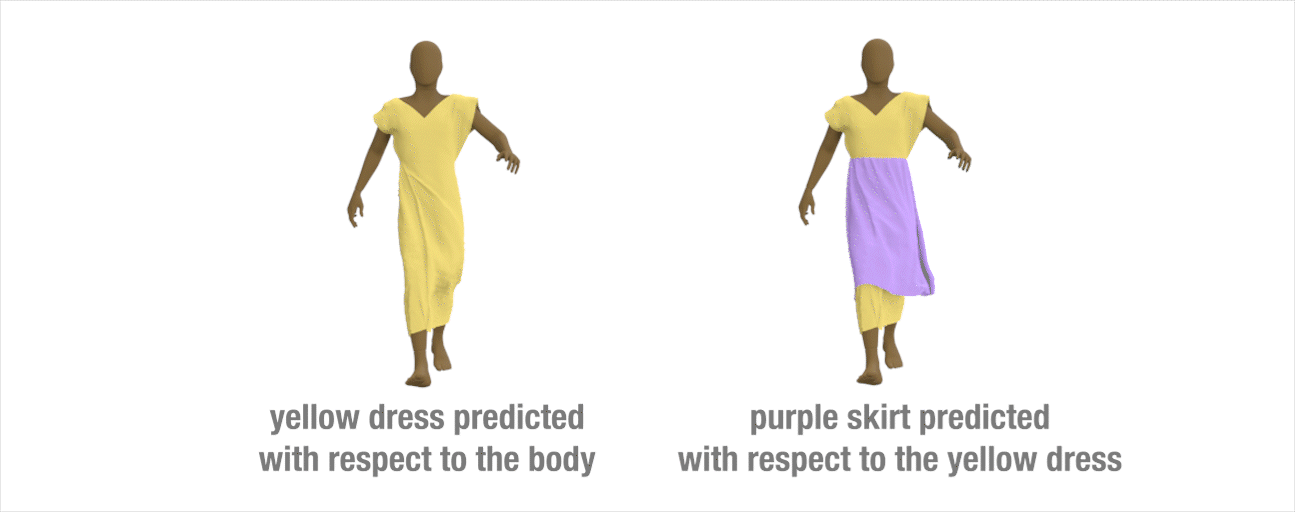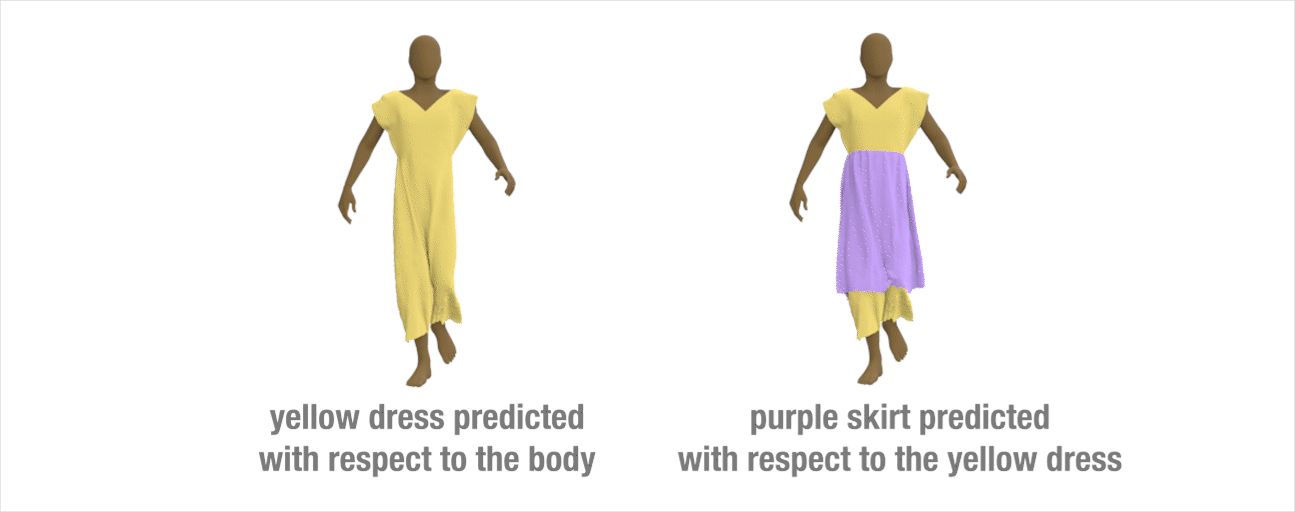
Our method can be extended to handle multi-layer garments. We train a network to predict how the yellow dress would deform based on the underlying body motion. Then, we train a second network to learn how the purple skirt deforms treating the yellow dress as the interaction body.