Sébastien Ehrhardt1,*
Oliver Groth1,*
Áron Monszpart2,3
Martin Engelcke1
Ingmar Posner1
Niloy J. Mitra2,4
Andrea Vedaldi1
1Oxford University
2University College London
3Niantic
4Adobe Research
NeurIPS 2020
(conditional accept)
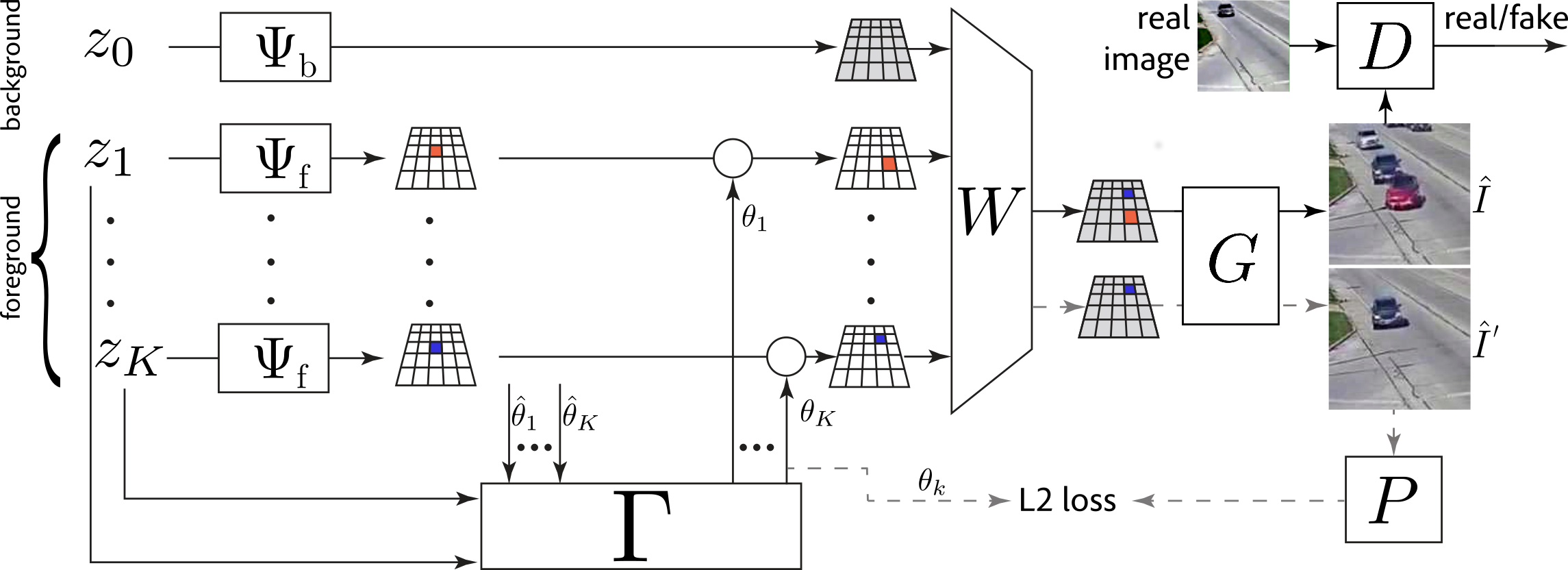
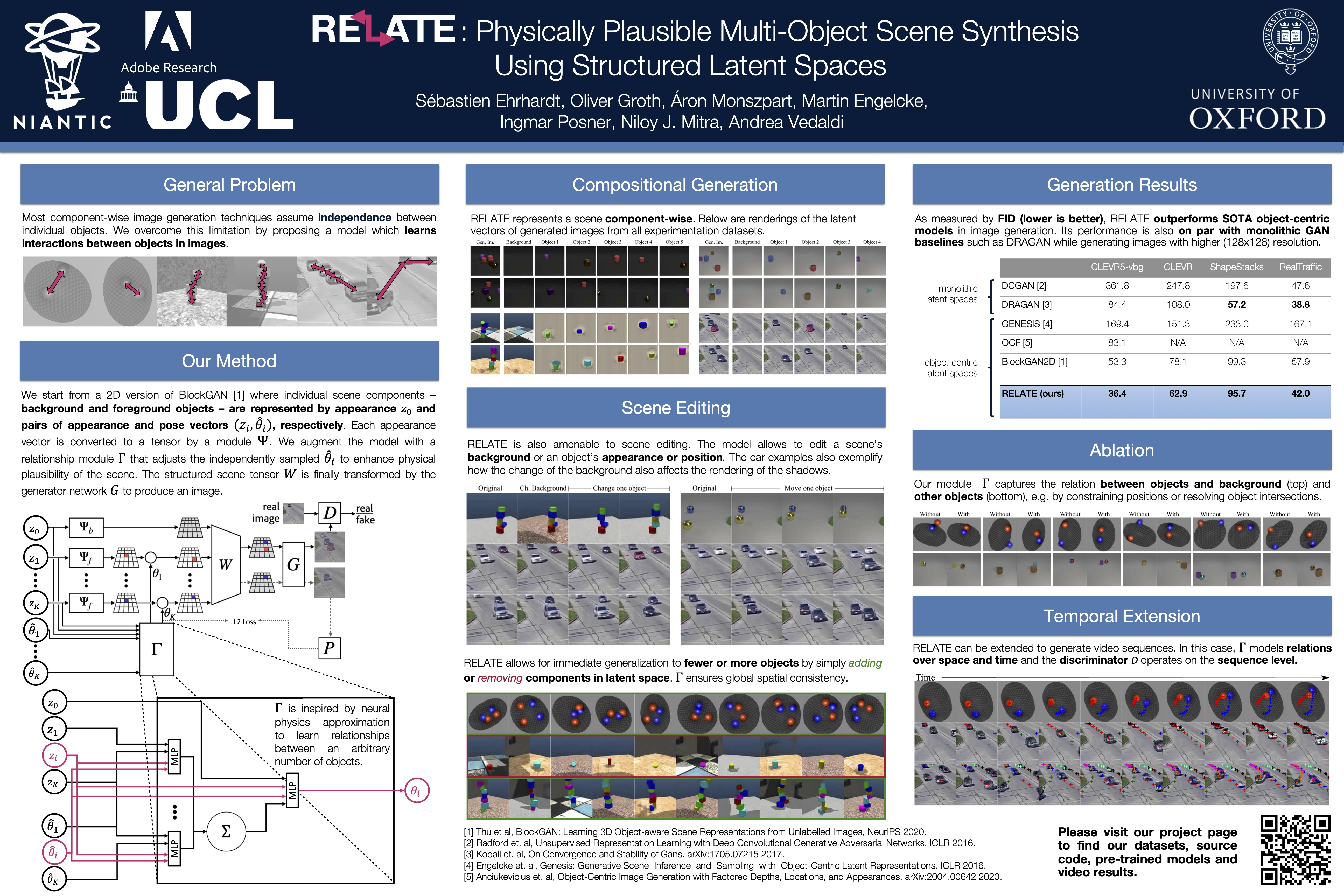
We present RELATE, a model that learns to generate physically plausible scenes and videos of multiple interacting objects. Similar to other generative approaches, RELATE is trained end-to-end on raw, unlabeled data. RELATE combines an object-centric GAN formulation with a model that explicitly accounts for correlations between individual objects. This allows the model to generate realistic scenes and videos from a physically-interpretable parameterization. Furthermore, we show that modeling the object correlation is necessary to learn to disentangle object positions and identity. We find that RELATE is also amenable to physically realistic8scene editing and that it significantly outperforms prior art in object-centric scene generation in both synthetic (CLEVR, ShapeStacks) and real-world data (cars). In addition, in contrast to state-of-the-art methods in object-centric generative modeling, RELATE also extends naturally to dynamic scenes and generatesvideos of high visual fidelity.

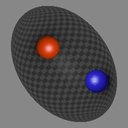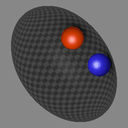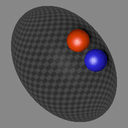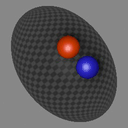
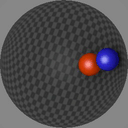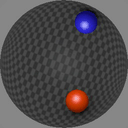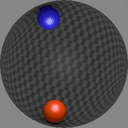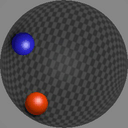
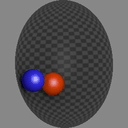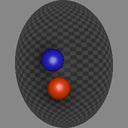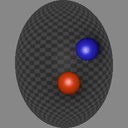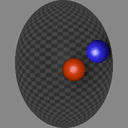
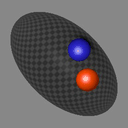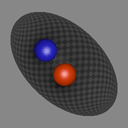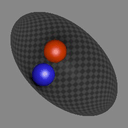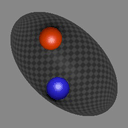
We show consecutive video frames generated by RELATE overlayed with crosses representing projections of the model’s estimated pose parameters for each object. In BALLSINBOWL the interaction with the environment is well captured as the balls stay within the bowl. In REALTRAFFIC the cars stay in their lane, or can decide to make a right turn (last row).
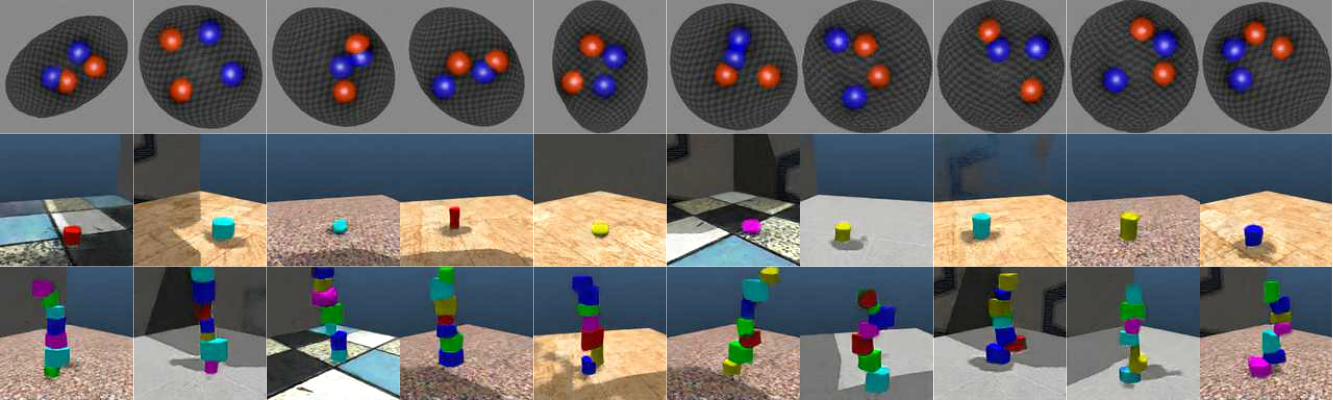
RELATE can generate images outside the training distribution. The first row shows generating a bowl with four balls, whereas the training set only features exactly two. The last two rows depict towers of one and seven objects, whereas the training images only had stacks of height two to five.






















































































































@article{EhrhardtGrothEtAl:RELATE:NeurIPS:2020,
title={{RELATE}: Physically Plausible Multi-Object Scene Synthesis Using Structured Latent Spaces},
author={Ehrhardt, {S\'ebastien} and Groth, Oliver and Monszpart, Aron and Engelcke, Martin and Posner, Ingmar and {J. Mitra}, Niloy and Vedaldi, Andrea},
journal={{NeurIPS}},
year={2020}
}
This work is supported by the European Research Council under grants ERC 638009-IDIU, ERC 677195-IDIU, and ERC 335373. The authors acknowledge the use of Hartree Centre resources in this work. The STFC Hartree Centre is a research collaboratory in association with IBM providing High Performance Computing platforms funded by the UK’s investment in e-Infrastructure. The authors also acknowledge the use of the University of Oxford Advanced Research Computing (ARC) facility in carrying out this work (http://dx.doi.org/10.5281/zenodo.22558). The authors also thank Olivia Wiles for feedback on the paper draft, Thu Nguyen-Phuoc for providing the implementation of BlockGAN and Titas Anciukevicius for providing the generation code for CLEVR variants. We finally thank anonymous reviewers for precious feedback.