A Multi-Implicit Neural Representation for Fonts
Pradyumna Reddy1 Zhifei Zhang2 Matthew Fisher2 Hailin Jin2 Zhaowen Wang2 Niloy J. Mitra1,2
1University College London 2 Adobe Research
NeurIPS 2021

Abstract
Fonts are ubiquitous across documents and come in a variety of styles. They are either represented in a native vector format or rasterized to produce fixed resolution images. In the first case, the non-standard representation prevents benefiting from latest network architectures for neural representations; while, in the latter case, the rasterized representation, when encoded via networks, results in loss of data fidelity, as font-specific discontinuities like edges and corners are difficult to represent using neural networks. Based on the observation that complex fonts can be represented by a superposition of a set of simpler occupancy functions, we introduce multi-implicits to represent fonts as a permutation-invariant set of learned implict functions, without losing features (e.g., edges and corners). However, while multi-implicits locally preserve font features, obtaining supervision in the form of ground truth multi-channel signals is a problem in itself. Instead, we propose how to train such a representation with only local supervision, while the proposed neural architecture directly finds globally consistent multi-implicits for font families. We extensively evaluate the proposed representation for various tasks including reconstruction, interpolation, and synthesis to demonstrate clear advantages with existing alternatives. Additionally, the representation naturally enables glyph completion, wherein a single characteristic font is used to synthesize a whole font family in the target style.
Reconstruction
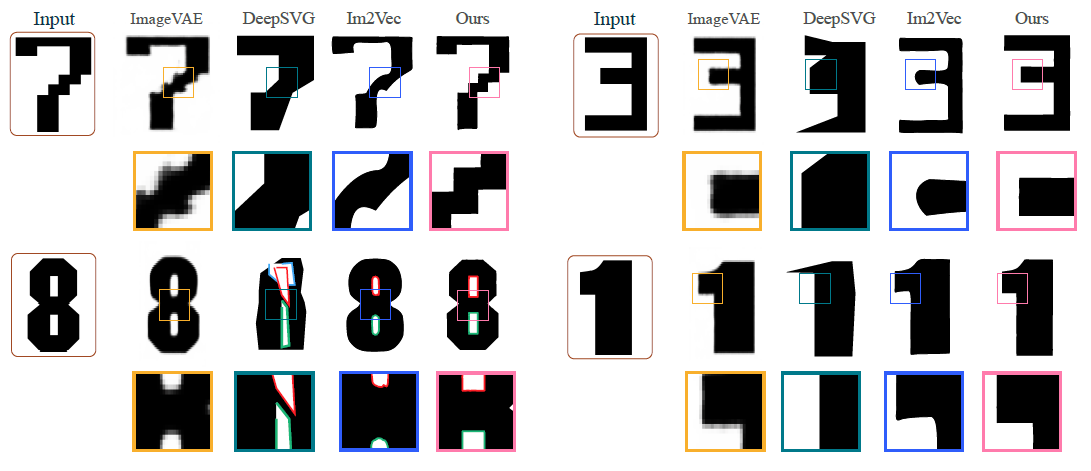
Reconstruction examples (baseline vs. ours) with zoom-in box highlighting corners..
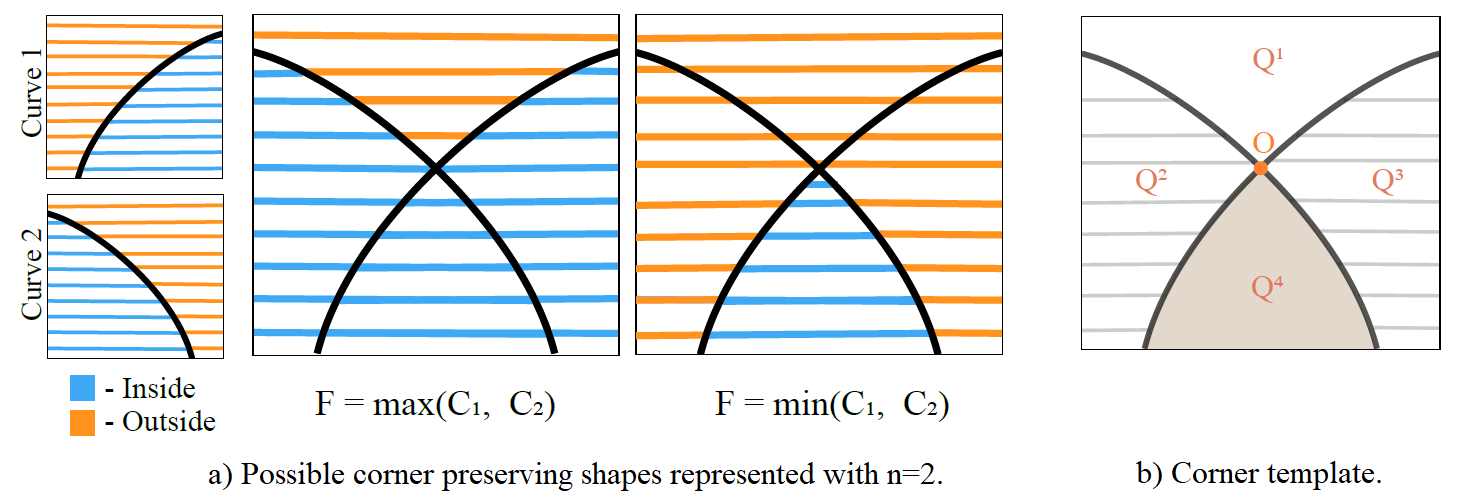
Corner Templates Overview
We will lose details like sharp corners when upscaling bitmaps or sign distance functions. Resampling an implicit model that encodes the pixel values or signed distance values of a shape similarly suffers from blurry corners. An brute force solution is to train the implicit model with extremely highresolution images, but this would drastically increase the burden of training, and still limited by the training resolution. Rather than directly modeling corners, we represent corners as the intersection of multiple curves
Font Completion
In the inference stage, given an unseen glyph, we first find the optimal latent vector (i.e., font style) that makes the rendered glyph closest to the given glyph. More specifically, fixing the glyph label based on the given glyph, its font latent vector z^ can be obtained by minimizing the distance between the raster of the given glyph and the predicted glyph using gradient descent. With the optimal z^, all the other glyphs with the same font style can be generated by iterating the glyph label.To generate new fonts and the corresponding glyphs, first the implicit model is trained with latent vector z and glyph label (i.e., one-hot encoding) concatenated to spatial locations as the input. Font completion examples (ours) with zoom-in boxes highlighting the corners.

Font completion using a Partial Glyph
Glyph completion example. Given a partial glyph unseen in the training set, our method can complete the given glyph and other glyphs with the same font style.

Bibtex
@article{reddy2021multi,
title={A Multi-Implicit Neural Representation for Fonts},
author={Reddy, Pradyumna and Zhang, Zhifei and Fisher, Matthew and Jin, Hailin and Wang, Zhaowen and Mitra, Niloy J},
journal={arXiv preprint arXiv:2106.06866},
year={2021}
}
Reference
Also checkout our previous work on Synthesizing Vector Graphics without Vector Supervision at http://geometry.cs.ucl.ac.uk/projects/2021/im2vec/.