Search for Concepts: Discovering Visual Concepts Using Direct Optimization
Pradyumna Reddy1 Paul Guerrero2 Niloy J. Mitra1,2
1University College London 2 Adobe Research
BMVC 2022

Abstract
Finding an unsupervised decomposition of an image into individual objects is a key step to leverage compositionality and to perform symbolic reasoning. Traditionally, this problem is solved using amortized inference, which does not generalize beyond the scope of the training data, may sometimes miss correct decompositions, and requires large amounts of training data. We propose finding a decomposition using direct, unamortized optimization, via a combination of a gradient-based optimization for differentiable object properties and global search for non-differentiable properties. We show that using direct optimization is more generalizable, misses fewer correct decompositions, and typically requires less data than methods based on amortized inference. This highlights a weakness of the current prevalent practice of using amortized inference that can potentially be improved by integrating more direct optimization elements.
Pipeline

Overview of our approach. Given an image dataset I = {I_1, . . . , I_N }, we alternate between updating element parameters θ (such the choice of visual concept τ, its position, scale, etc.) and the visual concepts V. We iterate over multiple target images Ik before evolving V by cloning concepts that are used often and have a large error. Another m iterations specialize the cloned concepts to better reconstruct the target images. The result of this iterative procedure is a library of visual concepts that can be used to efficiently decompose any image that makes use of similar visual concepts.
Out of distribution generalization
The visual concepts learned on one dataset (MNIST, left), can generalize to a second dataset (EMNIST, right), without further training.

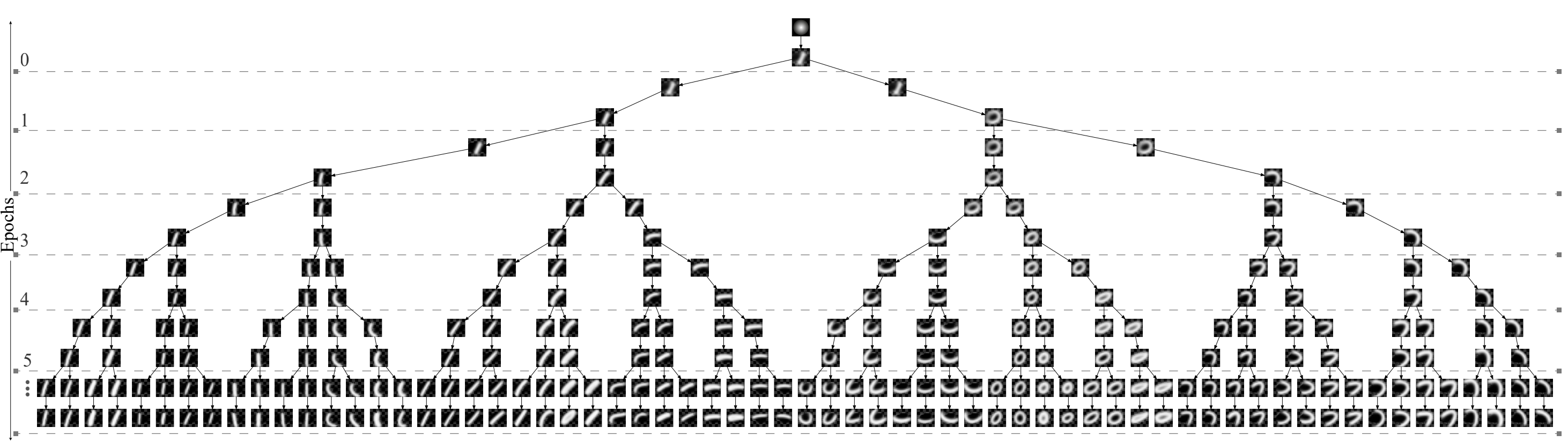
Concept Evolution Graph
Visual concept evolution for the MNIST dataset. Note how the concepts evolve over optimization epochs by specializing to subtle stroke variations.
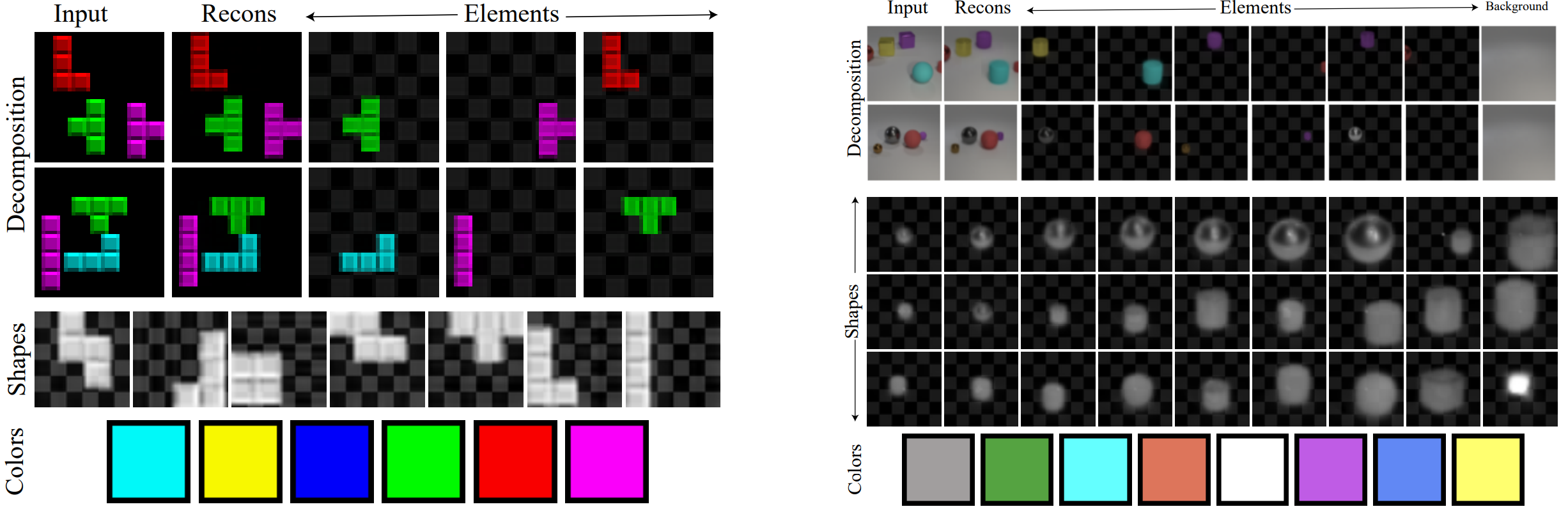
Decomposition Results
Decomposition result on the Tetris dataset (left) and Clevr dataset (right), showing composite concepts consisting of both learned shapes and learned hues. Since we do not include mirroring or scaling in our image formation model, mirrored objects and objects at different depths are learned as separate concepts.
Our Method compared with MarioNette and recovered concepts.

Bibtex
@misc{https://doi.org/10.48550/arxiv.2210.14808,
doi = {10.48550/ARXIV.2210.14808},
url = {https://arxiv.org/abs/2210.14808},
author = {Reddy, Pradyumna and Guerrero, Paul and Mitra, Niloy J.},
title = {Search for Concepts: Discovering Visual Concepts Using Direct Optimization},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
Reference
Also checkout our previous work on Synthesizing Vector Graphics without Vector Supervision at http://geometry.cs.ucl.ac.uk/projects/2021/im2vec/.