Learning Semantic Deformation Flows with 3D Convolutional Networks
- M. Ersin Yumer1
- Niloy J. Mitra2
1Adobe Research 2University College London
ECCV 2016
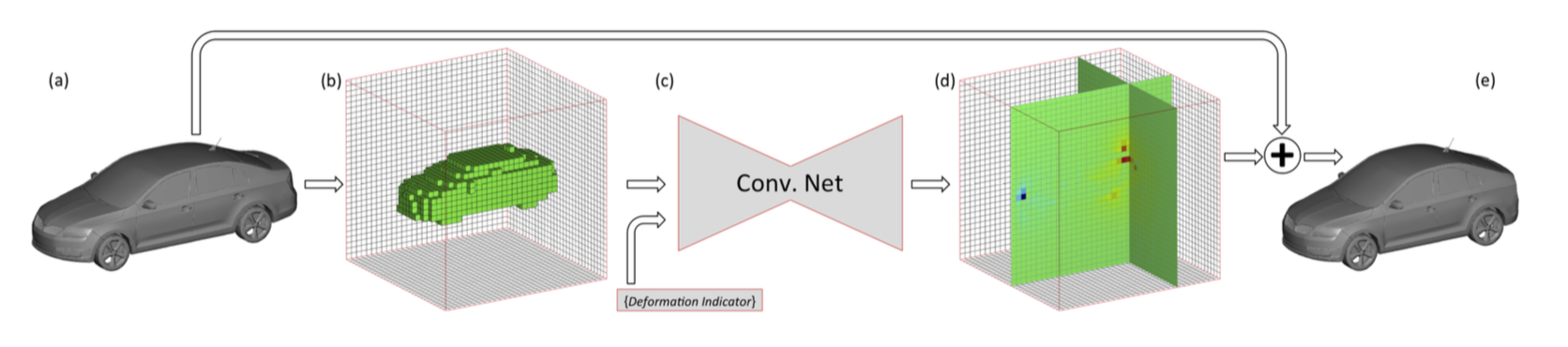
Our 3D convolutional network (c) takes a volumetric representation (b) of an object (a) and high-level deformation intentions as input and predicts a deformation flow (d) at the output. Applying the predicted deformation flow to the original object yields a high quality novel deformed version (e) that displays the high-level transformation intentions (In this illustration, the car is deformed to be more compact).
Abstract
Shape deformation requires expert user manipulation even when the object under consideration is in a high fidelity format such as a 3D mesh. It becomes even more complicated if the data is represented as a point set or a depth scan with significant self occlusions. We introduce an end-to-end solution to this tedious process using a volumetric Convolutional Neural Network (CNN) that learns deformation flows in 3D. Our network architectures take the voxelized representation of the shape and a semantic deformation intention (e.g., make more sporty) as input and generate a deformation flow at the output. We show that such deformation flows can be trivially applied to the input shape, resulting in a novel deformed version of the input without losing detail information. Our experiments show that the CNN approach achieves comparable results with state of the art methods when applied to CAD models. When applied to single frame depth scans, and partial/noisy CAD models we achieve ∼60% less error compared to the state-of-the-art.
Overview
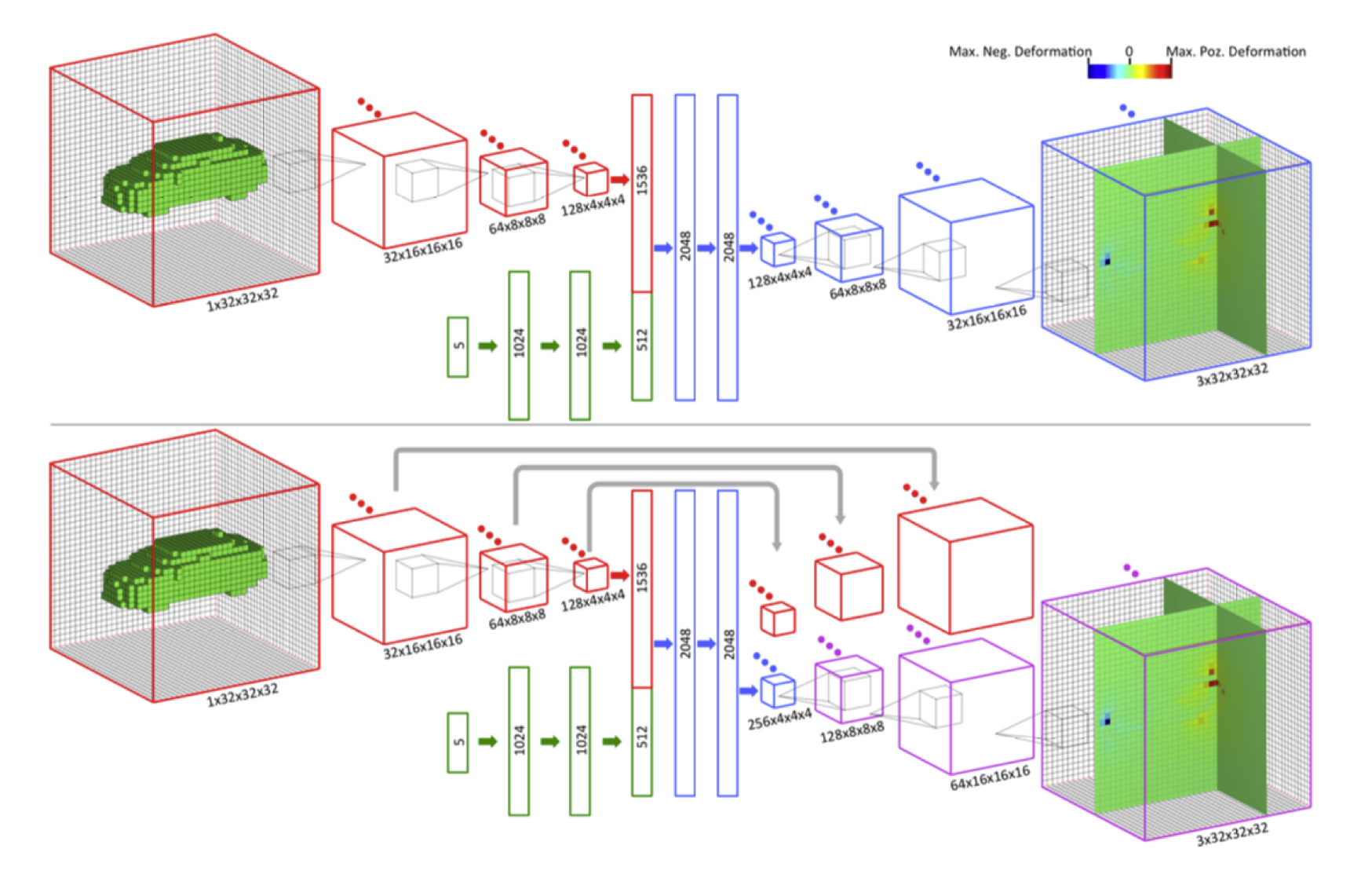
Fig.2. Top: Volumetric convolutional encoder (red)’s third set of filter responses (128∗4×4×4) are fully connected to a layer of 1536 neurons, which are concatenated with the 512 codes of deformation indicator vector (green). After three fully connected layer mixing, convolutional decoder part (blue) generates a volumetric deformation flow (3∗32×32×32). Bottom: We add all filter responses from the encoder part to the decoder part at corresponding levels. (Only the far faces of input - output volume discretization is shown. The deformation flow is computed in the entire volume, where only two slices are shown for visual clarity. Arrows indicate fully connected layers, whereas convolution and upconvolution layers are indicated with appropriate filters.)
Bibtex
@inproceedings{yumer2016learning,
title = {Learning Semantic Deformation Flows with 3D Convolutional Networks},
author = {Yumer, M. E., and Mitra, N. J.},
booktitle={European Conference on Computer Vision (ECCV 2016)},
organization = {Springer},
pages = {-},
year = {2016},
}
Links

Paper (6.1MB)

Supplementary Material (557KB)